Spark Streaming in production & how it works
Reading Time: 4 minutes

This is our next blog in the series of blogs about Spark Streaming.
After talking about Spark Streaming and how it works, now we will look at how to implement Spark structured streaming in production. At Sigmoid we have implemented Spark Streaming in production for some customers and have achieved great results by improving the design and architecture of the system. This blog post is about the design considerations and key learning for implementing Spark structured Streaming in a production environment.
Most Real time Analytics Systems can be broken down into a Receiver System, a Stream Processing System and a Storage System.
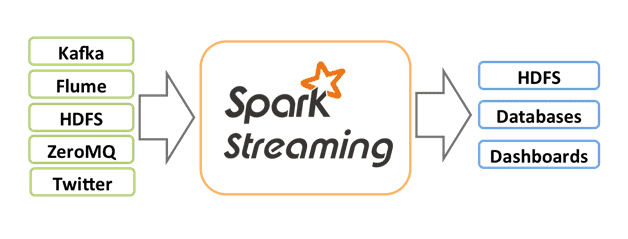
A good design/architecture is essential for the success of any application. A well designed system is stable, maintainable and scalable. With the design done correctly, maintenance and upgrade efforts can be minimized, which in turn keeps the costs low. Good design practices have been learnt and implemented while working on Spark Streaming at Sigmoid. Further we talk about how we can design Stable and maintainable systems with Spark Streaming.
Spark Streaming in Production
Stability
The system must be stable to overcome any unplanned outages as such outages might make clients furious and leave the user base frustrated.
Fault tolerance – Any production system should be capable of recovering from failures. Fault Tolerance is even more important for a real-time analytics system. Apart from creating a fault tolerant Streaming Processing System, your Receiver needs to be fault tolerant too.
- Developing Akka based custom receivers with a supervisor allows you to create auto healing receivers. To Create a Supervisor for your actor, the actor needs to implement SupervisorStratergy. You can look atakkaworhdcount for implementing your custom Akka receiver
- Using auto healing connection pools avoids exhaustion of the connection pool
- Track your output – The time interval and size of your output are the most suited parameters to set up alerting in your system. Setting up alerting to track these parameters makes more sense as it covers for failure scenarios at any point in your pipeline.
- Insert timestamps in your data to track the latest updates
- Setup alerts to track huge changes to the output size
The below code depicts this
| // Restart the storage child when StorageException is thrown. // After 3 restarts within 5 seconds it will be stopped.private static SupervisorStrategy strategy = new OneForOneStrategy(3,Duration.create(“5 seconds”), new Function<Throwable, Directive>() { @Override public Directive apply(Throwable t) { if (t instanceof StorageException) { return restart(); } else{ return escalate(); }} }); |
Maintainability
Systems need to be designed in a modular way, this helps in bringing down the development and maintenance costs. It is easy to customize or update modular systems. Bugs can be easily fixed without creating unwanted side effects. A good modular approach creates reusable components. We can safely say modularity brings maintainability.
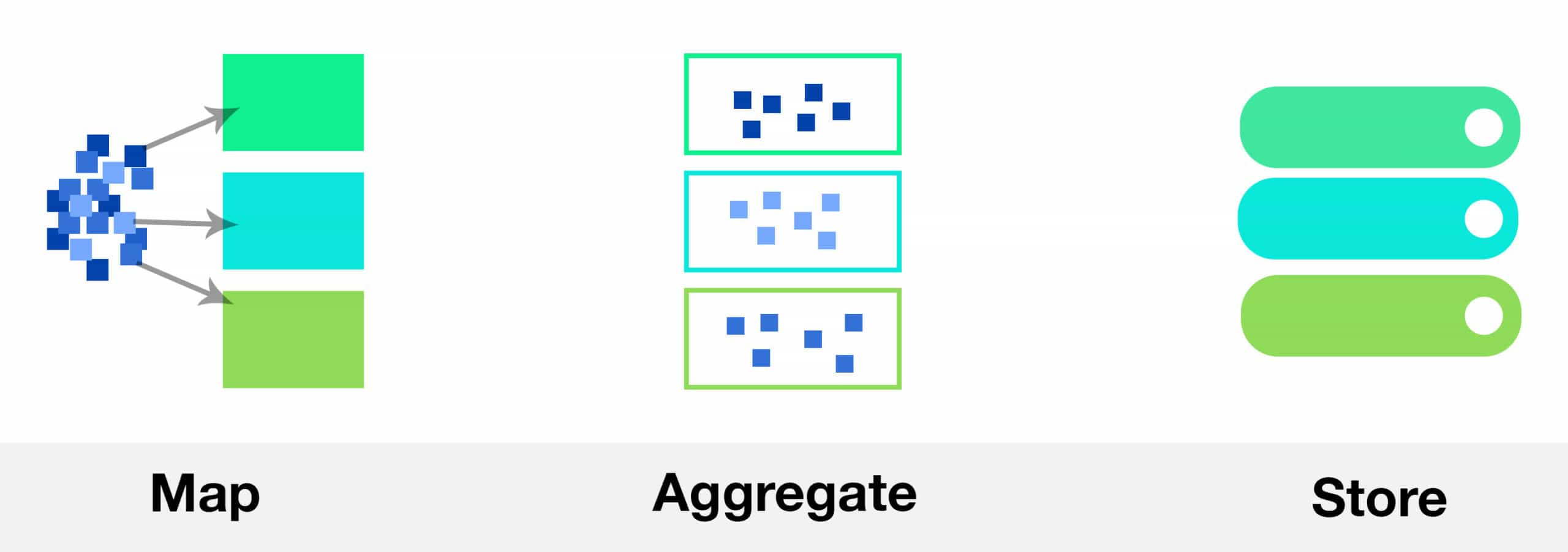
The Stream processing system can be further divided into 3 subparts – Map, Aggregate and Store.
- Map: Avoid the use of anonymous functions, as they are difficult to test and even more difficult to maintain. They can’t be tested without initializing a spark context. Move your logic out of your spark code, this would make your code more modular. This would allow you to write better Unit test cases, you can test your functions without initializing a Spark Context.
- Aggregation: In the aggregation layer, Monoids allow to move the logic away from Spark code. In a crude way, Monads are classes which perform associative operations and can be plugged into spark code to perform Streaming operations.
- Store: It is preferable to use NoSQL databases over HDFS for Streaming Applications because NoSQL databases allow the application to make incremental updates. Also NoSQL Databases allow you to query the data, this is essential to verify the output of your job and test the system, this is not possible in HDFS.
| object LongMonoid extends Monoid[(Long, Long, Long)] { def zero = (0, 0, 0) def plus(r: (Long, Long, Long), l: (Long, Long, Long)) = { (l._1 + r._1, l._2 + r._2, l._3 + r._3) }} |
Twitter Algebird provides an API of monads, pretested and helps save a lot of development and testing effort.
Testing your System
If the system is well designed, testing involves lesser effort and resources. A good set of automated test cases is essential to make enhancements and improvements to your system. The test cases need to have as much coverage as possible. But for functional testing, you don’t want to spin a cluster. You should also try to avoid writing integrated test cases. It’s suitable to write unit tests, and you can test your map functions and monads independently.
About the Author
Arush was a technical team member at Sigmoid. He was involved in multiple projects including building data pipelines and real time processing frameworks.




