Improving data processing with Spark 3.0 & Delta Lake
Reading Time: 7 minutes

Collecting, processing, and carrying out analysis on streaming data, in industries such as ad-tech involves intense data engineering. The data generated daily is huge (100s of GB data) and requires a significant processing time to process the data for subsequent steps.
Another challenge is the joining of datasets to derive insights. Each process on average has more than 10 datasets and an equal number of joins with multiple keys. The partition size for each key is unpredictable on each run.
And, finally, if the amount of data exceeds on certain occasions, the storage may run out of memory. This means that the process would die in the middle of the final writes, making consumers distinctly read the input data frames.
In this blog, we will cover an overview of Delta Lakes, its advantages, and how the above challenges can be overcome by moving to Delta Lake and migrating to Spark 3.0 from Spark 2.4.
What is Delta Lake?
Developed at Databricks, “Delta Lake is an open-source data storage layer that runs on the existing Data Lake and is fully cooperative with Apache Spark APIs. Along with the ability to implement ACID transactions and scalable metadata handling, Delta Lakes can also unify the streaming and batch data processing”.
Source: Databricks
Delta Lake uses versioned Parquet files to store data in the cloud. Once the cloud location is configured, Delta Lake tracks all the changes made to the table or blob store directory to provide ACID transactions.
Advantages of using Delta Lakes
Delta lake allows thousands of data to run in parallel, address optimization and partition challenges, faster metadata operations, maintains a transactional log and continuously keeps updating the data. Below we discuss a few major advantages:
Delta Lake Transaction Log
Delta lake transaction logs are an append-only file and contain an ordered record of all transactions performed on the Delta Lake table. The transaction log allows various users to read and write to the given table in parallel. It acts as a single source of truth or the central repository that logs all changes made to the table by the user. It maintains atomicity and continuously watches the transactions performed on Delta Lake.
As mentioned above, Spark checks the delta log for any new transactions, following which Delta Lake ensures that the user’s version is always in sync with the master record. It also ensures that no conflicting changes are being made to the table. If the process crashes before updating the delta log, the files will not be available to any reading processes as the reads always go through the transaction log.
Transaction Log Working and Atomic Commits
Delta lake does a checkpoint on every ten commits. The checkpointed file contains the current state of the data in the Parquet format which can be read quickly. When multiple users try to modify the table at the same time, Delta Lake resolves the conflicts using optimistic concurrency control.
The schema of the metadata is as follows:
| Column | Type | Description |
|---|---|---|
| format | string | Format of the table, that is, “delta”. |
| id | string | Unique ID of the table |
| name | string | Name of the table as defined in the metastore |
| description | string | Description of the table. |
| location | string | Location of the table. |
| createdAt | timestamp | When the table was created |
| partitionColumns | array of strings | Names of the partition columns if the table is partitioned |
| numFiles | long | Number of the files in the latest version of the table |
| properties | String-string map | All properties set for this table |
| minReaderVersion | int | Minimum version of readers (according to the log protocol) that can read the table. |
| minWriterVersion | int | Minimum version of readers (according to the log protocol) that can write to the table. |
Source: GitHub
Add and Remove File
Whenever a file is added or an existing file is removed, these actions are logged. The file path is unique and is considered as the primary key for the set of files inside it. When a new file is added on a path that is already present in the table, statistics and other metadata on the path are updated from the previous version. Similarly, remove action is indicated by timestamp. A remove action remains in the table as a tombstone until it has expired. A tombstone expires when the TTL (Time-To-Live) exceeds.
Since actions within a given Delta file are not guaranteed to be applied in order, it is not valid for multiple file operations with the same path to exist in a single version.
The dataChange flag on either an ‘add’ or ‘remove’ can be set to false to minimize the concurrent operations conflicts.
The schema of the add action is as follows:
| Field Name | Data Type | Description |
|---|---|---|
| path | String | A relative path, from the root of the table, to a file that should be added to the table |
| partitionValues | Map[String,String] | A map from partition column to value for this file. |
| size | Long | The size of this file in bytes |
| modificationTime | Long | The time this file was created, as milliseconds since the epoch |
| dataChange | Boolean | When false the file must already be present in the table or the records in the added file must be contained in one or more remove actions in the same version |
| stats | Statistics Struct | Contains statistics (e.g., count, min/max values for columns) about the data in this file |
| tags | Map[String,String] | Map containing metadata about this file |
The schema of the remove action is as follows:
milliseconds since the epochdataChangeBooleanWhen false the records in the removed file must be
contained in one or more add file actions in the same
versionextendedFileMetadataBooleanWhen true the fields partitionValues, size, and tags
are presentpartitionValuesMap[String, String]A map from partition column to value for this file. See
also Partition Value SerializationsizeLongThe size of this file in bytestagsMap[String, String]Map containing metadata about this file
| Field Name | Data Type | Description |
|---|---|---|
| path | string | An absolute or relative path to a file that should be removed from the table |
Source: GitHub
The schema of the metadata contains the file path on each add/remove action and the Spark read process does not need to do a full scan to get the file listings.
If a write fails without updating the transaction log, since the consumer’s reading will always go through the metadata, those files will be ignored.
Advantages of migrating to Spark 3.0
Apart from leveraging the benefits of Delta Lake, migrating to Spark 3.0 improved data processing in the following ways:
Skewed Join Optimization
Data skew is a condition in which a table’s data is unevenly distributed among partitions in the cluster and can severely downgrade the performance of queries, especially those with joins. Skewness can lead to extreme imbalance in the cluster thereby increasing the data processing time.
The data skew condition can be handled mainly by three approaches.
- Using the configuration “spark.sql.shuffle.partitions” for increased parallelism on more evenly distributed data.
- Increasing the broadcast hash join threshold using the configuration spark.sql.autoBroadcastJoinThreshold to the maximum size in bytes for the table that has to be broadcasted to all worker nodes during performing a join.
- Key Salting (Add prefix to the skewed keys to make the same key different and then adjust the data distribution).
Spark 3.0 has added an optimization to auto handling skew join based on the runtime statistics with the new adaptive execution framework.
Skewed Partition Condition
The challenge of skewed partitions that existed in the previous version of the Spark 2.4 had a huge impact on the network time and execution time of a particular task. Moreover, the methods to deal with it were mostly manual. Spark 3.0 overcomes these challenges.
The skewed partition will have an impact on the network traffic and on the task execution time, since this particular task will have much more data to process.
The skewed join partition is calculated by the data size and row counts from the runtime map statistics.
Optimization
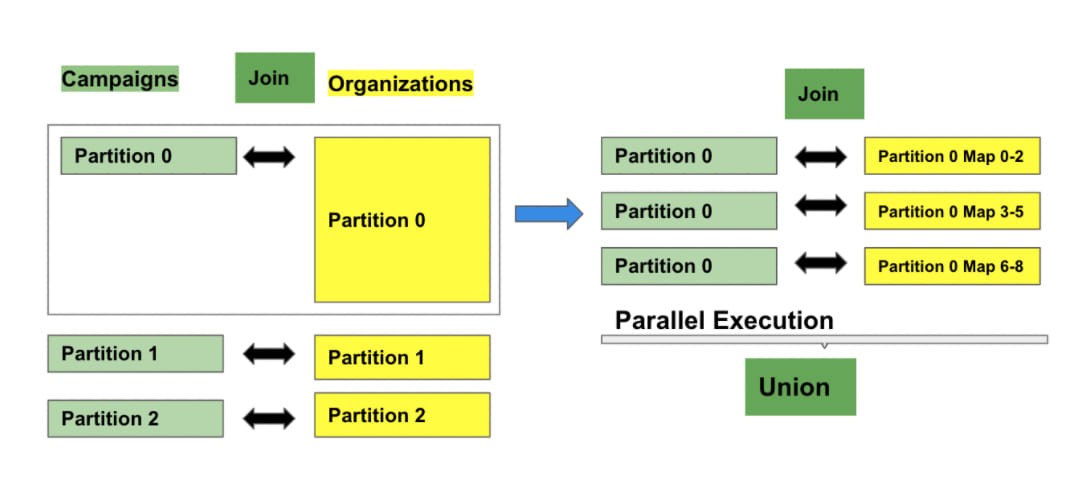
Adapted from: Apache Spark Jira
From the above table, the Dataframe Campaigns joins with the Dataframe Organizations. One of the partitions (Partition 0) from Organizations is big and skewed. Partition 0 is the result of 9 maps from the previous stage(Map-0 to Map-8). Spark’s OptimizeSkewedJoin rule will split the Partition into 3 and then create 3 separate tasks each one being a partial partition from Partition 0 (Map-0 to Map-2, Map-3 to Map-5, and Map-6 to Map-9) and joins with the Campaigns Partition 0. This approach results in additional cost by reading Partition 0 of table Campaigns equal to the number of partial partitions from the table Organizations.
End Result
Using Delta Lake and Spark 3.0, we enabled the following results for the ad tech firm:
- The time of data processing was reduced from 15 hours to 5-6 hours
- 50% reduction in AWS EMR cost
- Preventing loss of data and death of processes which was a frequent occurrence when the system went out of memory or the processing stopped due to a glitch in the system
- Monitoring & Alerting features were installed to notify in case the process fails
- Complete orchestration using Airflow to achieve full automation and dependency management between processes
Author
Rahul Radhakrishnan is a Technical Lead in the Data Engineering team at Sigmoid. He has 14 years of experience in the Software Industry with expertise on Big-Data technologies, back-end server-side development and applications development. He has worked in various domains like multimedia, Ecommerce, Network Security and Digital Marketing.




