Rehydrate bulk archived data in Azure storage using PowerShell Script
Reading Time: 4 minutes

Azure blob storage provides data to be stored in three different tiers for cost optimization related to different use cases. There are three types of tiers in azure which helps organize our data based on our frequency of use case: Hot, Cool and Archive. It is to be noted that the access tier option is only available for Block Blobs. However, hot and cool tier have data that is online and can be accessed frequently and infrequently respectively but the data that is moved to the archive tier is offline which means it can’t be read or modified. In order to read or download a blob that is in the archive tier, it needs to be moved to the online tier, hot or cool and this process is called rehydration. If we want to rehydrate some selected data we can simply try using the console but if there is bulk data that is in archive it is not possible to manually rehydrate it from the console.
In this blog, we will be discussing how to rehydrate the bulk archived data. It is to be noted that a Lifecycle Management Rule can move objects from hot to cool, from hot to archive, or from cool to archive but not from Archive to cool or hot. Hence, a Lifecycle Management Rule will not make this work.
Prerequisite: An Azure Virtual Machine with powershell and as module installed with your azure account logged in.
Now switch to powershell terminal using command pwsh and create a file using vim cool.ps1 and paste the following script below and save the file.
Suppose we have a container raw/ that has multiple folders which has archive data. We will use the following PowerShell Script:
- Replace rgName with the resource group value of your storage account. accountName will have the name of the storage account. containerName will have the name of the container under which you have archived blobs.
- Then we will get the context of the storage account within the resource group specified.
- Then we will be listing all the blobs in the container and if the access tier of those blobs is Archive it will be changed to cool by SetAccessTier operation.
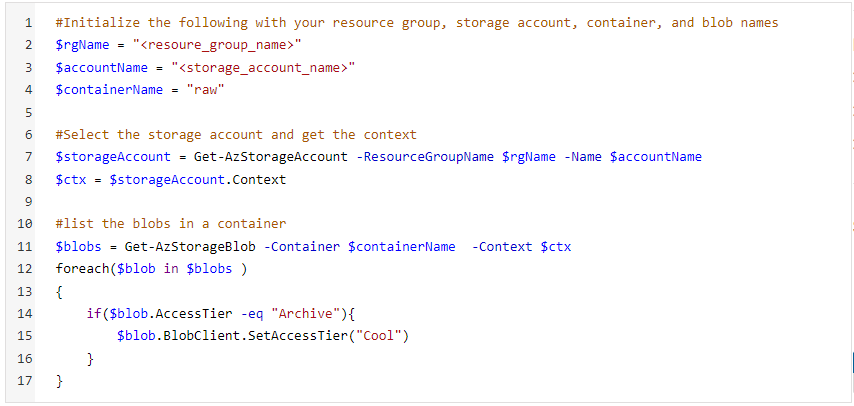
Rehydrating script in PowerShell
If you have multiple folders under the raw container, you can modify your script with something like the following:
Specify folders under your container in FolderName variables. A “*” would indicate that you are specifying all folders or blobs under that container or folder.
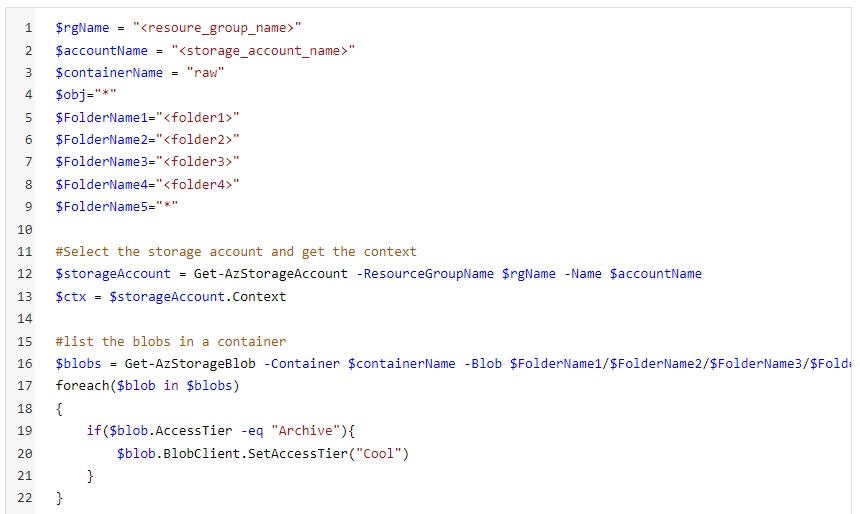
Rehydrating script with folder structure in PowerShell
- After saving the file, run a background job using the command:
- This will return the following output:

- You can get status of the job by running command: Get-Job
- To check output of Job use the following command:

You will get something like this:
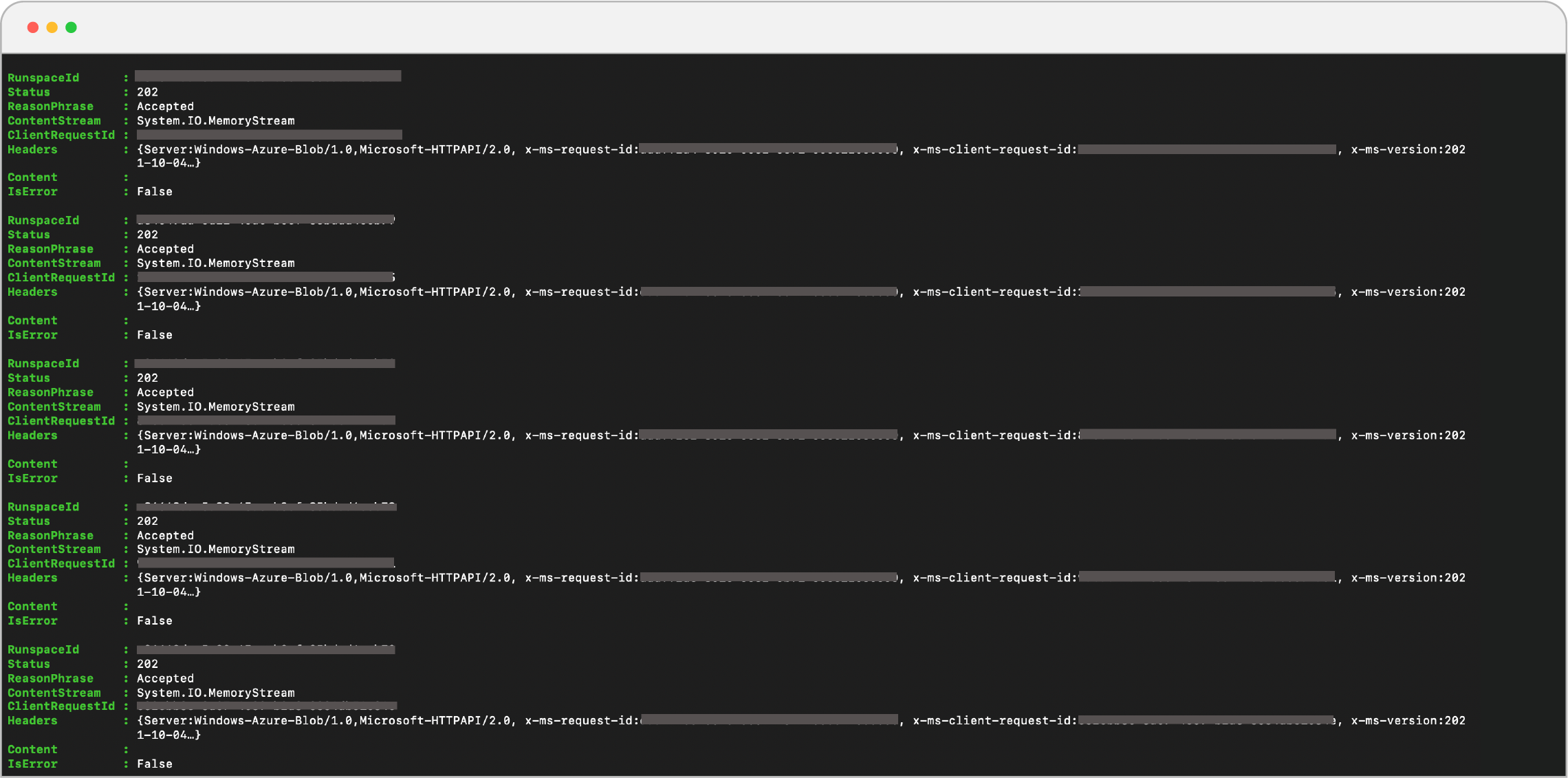
Output of Rehydrating script.
- Now go to the console, under archive status, you will notice that blobs are now rehydrating!!
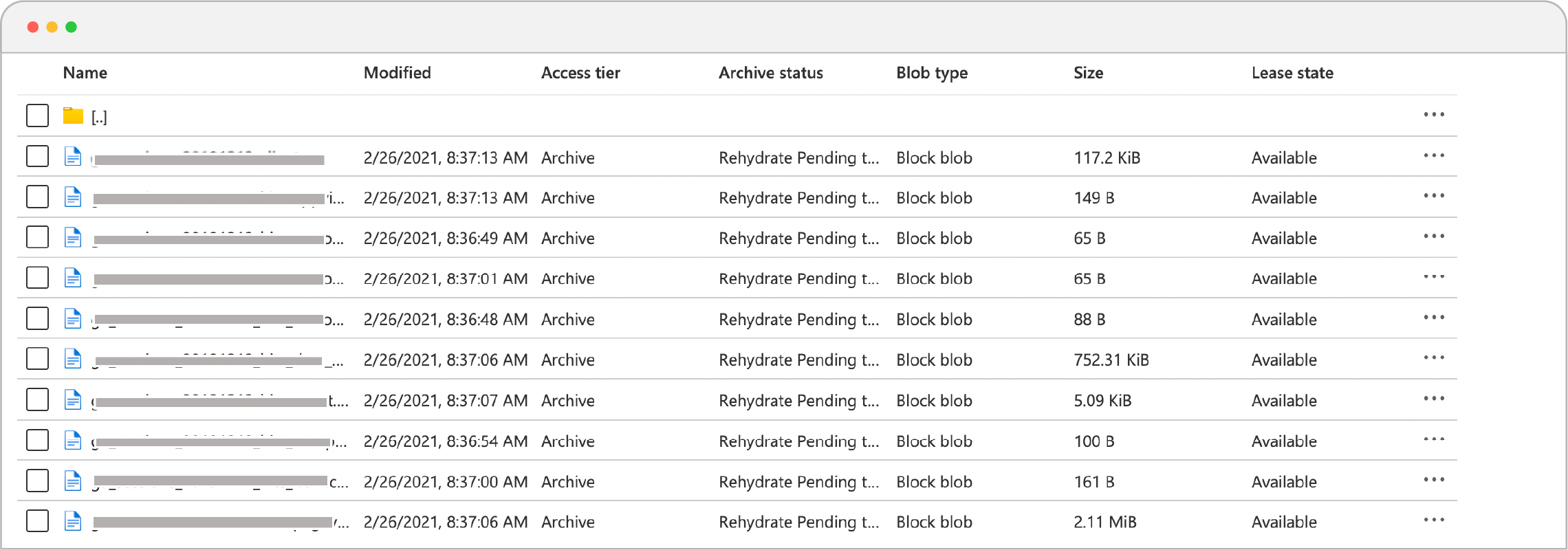
Rehydration Pending Status in Console.
Note: It can take several hours to rehydrate a blob from the Archive tier. Since we are not setting any priority then Standard priority is selected as default. A high priority rehydration is faster but it is costlier than standard-priority rehydration. It is recommended to select a high priority rehydration when data is needed to be restored in case of an emergency.
About the Author
Prajna Bahuguna is a DataOps Engineer at Sigmoid. She is a DevOps enthusiast who is always curious to learn about innovative solutions using Cloud, Python and DevOps practices. In her leisure time she enjoys doing artwork and mobile photography.
Featured blogs




Featured blogs