Process workflow for running Spark application on Kubernetes using Airflow
Reading Time: 8 minutes

In recent years, there has been a significant surge in companies using Spark on Kubernetes (K8s) and it’s no wonder why. The benefits that K8s offer have been the driving force behind this trend. In fact, a recent survey states that 96% of organizations are now either using or evaluating Kubernetes. As more and more businesses migrate to the cloud, the number of companies deploying Spark on Kubernetes continues to rise. However, it’s important to note that this approach does have its drawbacks. Enterprises that choose to run Spark with Kubernetes must be prepared to tackle the challenges that come with this solution. This means having a strong understanding of their infrastructure and being able to optimize its performance across multiple dimensions. Ultimately, success with Spark on Kubernetes depends on the ability to monitor and manage the platform effectively.
This blog will detail the steps for setting up a Spark App on Kubernetes using the Airflow scheduler. The goal is to enable data engineers to program the stack seamlessly for similar workloads and requirements.
Benefits of running Spark on Kubernetes
Kubernetes can save effort and provide a better experience while executing Spark jobs. In addition, deploying Spark on K8s solution could offer some benefits to the business:
- Scalability to meet any workload demands
- Monitoring compute nodes and automatically replaces instances in case of failure, ensuring reliability
- Portability to any cloud environment, making it less dependent on any particular cloud provider. This approach saves time in orchestrating, distributing, and scheduling Spark jobs across different cloud providers
- Cost-effectiveness by not relying on a specific cloud provider
- Ad-hoc monitoring for better visibility into the system’s performance
- Uses a common k8s ecosystem as with other workloads and offers features such as continuous deployment, role-based access control (RBAC), dedicated node-pools, and autoscaling, among others.
Understanding the technologies
Before moving to the setup part, let’s first have a quick look at all the technologies that will be covered ahead:-
- Kubernetes
- Spark
- Airflow
Kubernetes
Kubernetes is a container management system developed on the Google platform. Kubernetes helps to manage containerized applications in various types of physical, virtual, and cloud environments. Google Kubernetes is a highly flexible container tool to consistently deliver complex applications running on clusters of hundreds to thousands of individual servers.
Spark
Apache Spark is a distributed processing system for handling big data workloads. It is an open-source platform that leverages in-memory caching and optimized query execution to deliver fast queries on data of any size. Spark is designed to be a fast and versatile engine for large-scale data processing.
Airflow
Apache Airflow is an open-source platform designed for developing, scheduling, and monitoring batch-oriented workflows. Airflow provides an extensible Python framework that enables users to create workflows connecting with virtually any technology. The platform includes a web interface that helps manage the state of workflows. Airflow is highly versatile and can be deployed in many ways, ranging from a single process on a laptop to a distributed setup capable of supporting the largest data workflows.
Spark on Kubernetes using Airflow
Apache Spark is a high-performance open-source analytics engine designed for processing massive volumes of data using data parallelism and fault tolerance. Kubernetes, on the other hand, is an open-source container orchestration platform that automates application deployment, scaling, and management. When used together, Spark and Kubernetes offer a powerful combination that delivers exceptional results. Simply put, Spark provides the computing framework, while Kubernetes manages the cluster, providing users with an operating system-like interface for managing multiple clusters. This results in unparalleled cluster use and allocation flexibility, which can lead to significant cost savings.
The Spark on k8s operator is a great choice for submitting a single Spark job to run on Kubernetes. However, users often need to chain multiple Spark and other types of jobs into a pipeline and schedule the pipeline to run periodically. In this scenario, Apache Airflow is a popular solution. Apache Airflow is an open-source platform that allows users to programmatically author, schedule, and monitor workflows. It can be run on Kubernetes.
The current setup
Kubernetes is used to create a Spark cluster from which parallel jobs will be launched. The launch of the jobs are not managed directly through the master node of the Spark cluster but from another node running an instance of Airflow. This provides more control over the executed jobs as well as interesting features such as backfill execution. This consists in performing executions that correspond to past time from the current time, when the scheduling is defined. Airflow comprises a robust server and scheduler that provides a Python API for defining executors. With this API, programmers can specify tasks and their execution using a DAG (directed acyclic graph) format.
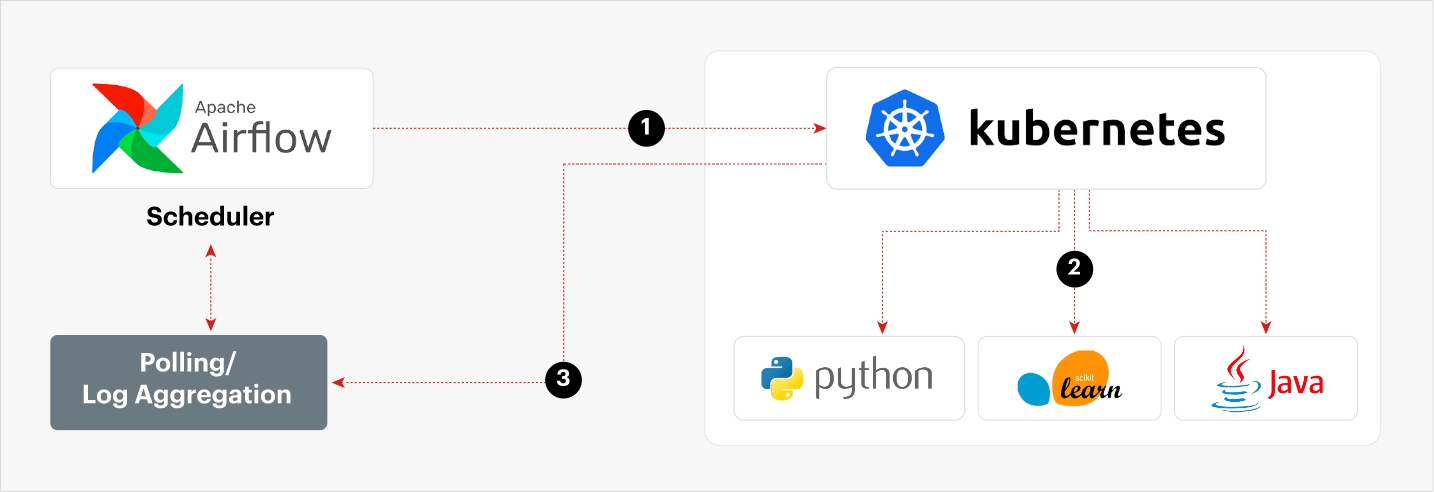
Source: Kubernetes.io
Steps to run Spark application on Kubernetes through Airflow schedule:
- Step 1 – Setting up Kubernetes Cluster
- Step 2 – Spark operator setup over Kubernetes
- Step 3 – Installation of Airflow over Kubernetes
Step 1: Setting up Kubernetes Cluster
The setup is done using RKE2. The RKE document captures all the steps on the installation process.
Step 2: Spark operator setup on Kubernetes (k8s)
2a. After setting up the k8s cluster, install spark-operator inside the k8s using the following command:
$ kubectl create namespace spark-operator
$ kubectl create namespace spark-jobs
$ helm repo add spark-operator
https://googlecloudplatform.github.io/spark-on-k8s-operator
$ helm install spark-operator/spark-operator --
namespace spark-operator --set webhook.enable=true
2b. Set k8s to run spark applications in the custom namespace by adding< –set sparkJobNamespace=spark-jobs>
$ helm install spark-operator spark-operator/spark-operator --namespace spark-operator --set webhook.enable=true --set sparkJobNamespace=spark-jobs
2c. Create a service account called spark and clusterrolebinding.
$ kubectl create serviceaccount spark -n spark-jobs $ kubectl create clusterrolebinding spark-role --clusterrole=edit -- serviceaccount=spark-jobs:spark --namespace=spark-jobs
Spark-operator setup is now complete.
2d. Next, the spark operator will be tested by submitting a sample spark application using a deployment file. Here’s how you can code the file:
sample.yaml
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: spark-jobs
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.4"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-
2.4.4.jar"
sparkVersion: "2.4.4"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 2.4.4
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.4
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
2e. Start the application
$ kubectl apply -f sample.yaml
2f. List out all sparkapplication jobs
$ kubectl get sparkapplication -n spark-jobs


2g. To check the spark application log, use the following command –
$ kubectl -n logs -f
Example is below:
$ kubectl -n spark-jobs logs -f spark-pi-driver
Step 3: Installation of Airflow On Kubernetes.
3a. Create namespace in k8s cluster
$ kubectl create namespace airflow
3b. Install Airflow using helm
$ git clone -b main https://github.com/airflow-helm/charts.git $ helm upgrade --install airflow charts/airflow -f values.yaml -n airflow $ helm upgrade --install airflow /home/ubuntu/airflow/charts/charts/airflow -f values.yaml --namespace airflow
Some of the changes that were pushed (for a specific requirement) in charts/charts/airflow/values.yaml, as follows-
3c. Changed executor type from CeleryExecutor to KubernetesExecutor

1. Disabled the Flower component

2. Disabled redis
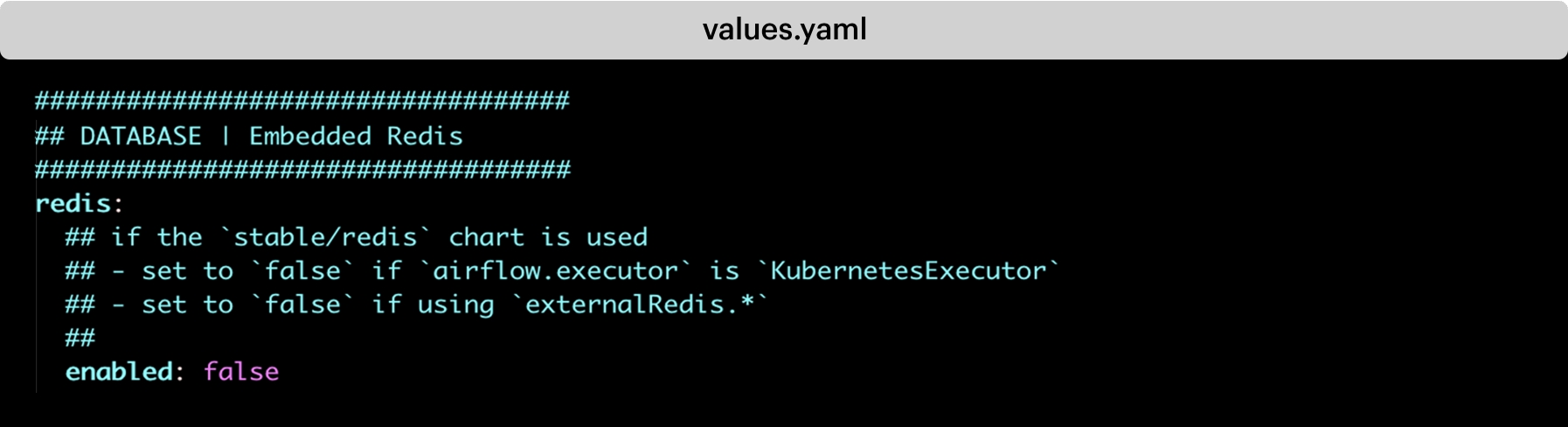
3. Added git repo url where airflow will check the DAG files –

4. Configured web UI user account for the defined users and roles with the access. The command shown below is a dummy. Programmers can completely customize this.

Once installation is done we can see the pods and services of airflow.
$ kubectl get pods -n airflow

$ kubectl get svc -n airflow

3d. Airflow can be connected by UI using airflow-web service with user account details which are configured in values.yaml file.
a. Next, create a kubernetes_conn_id from airflow web UI.
1. Select Admin>> connections>> select the connection>> create connection ID
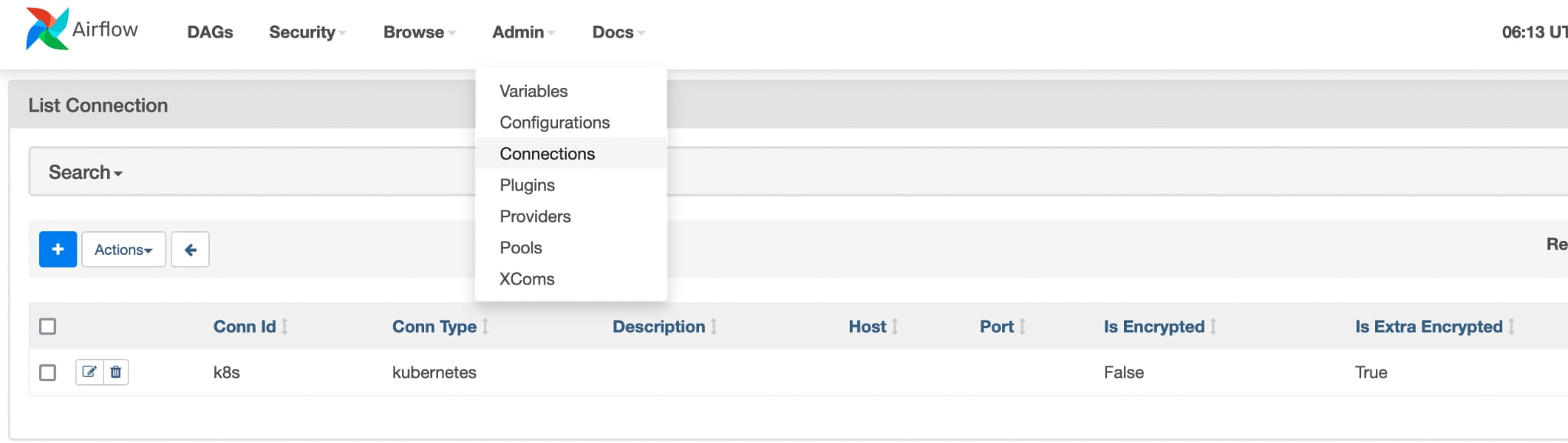
2. Sample DAG used for testing:
sample-dag.py
from airflow import DAG
from datetime import timedelta, datetime
from airflow.providers.cncf.kubernetes.operators.spark_kubernetes import
SparkKubernetesOperator
from airflow.providers.cncf.kubernetes.sensors.spark_kubernetes import
SparkKubernetesSensor
from airflow.models import Variable
from kubernetes.client import models as k8s
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
default_args={
'depends_on_past': False,
'email': ['[email protected]'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
with DAG(
'my-second-dag',
default_args=default_args,
description='simple dag',
schedule_interval=timedelta(days=1),
start_date=datetime(2022, 11, 17),
catchup=False,
tags=['example']
) as dag:
t1 = SparkKubernetesOperator(
task_id='n-spark-pi',
trigger_rule="all_success",
depends_on_past=False,
retries=3,
application_file="new-spark-pi.yaml",
namespace="spark-jobs",
kubernetes_conn_id="myk8s",
api_group="sparkoperator.k8s.io",
api_version="v1beta2",
do_xcom_push=True,
dag=dag
)
3. Sample new-spark-pi.yaml file:
new-spark-pi.yaml
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: spark-jobs
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.4"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar"
sparkVersion: "2.4.4"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 2.4.4
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.4
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
b. Once the DAG and spark application file is pushed into the configured repo, Airflow automatically picks the job and starts processing.
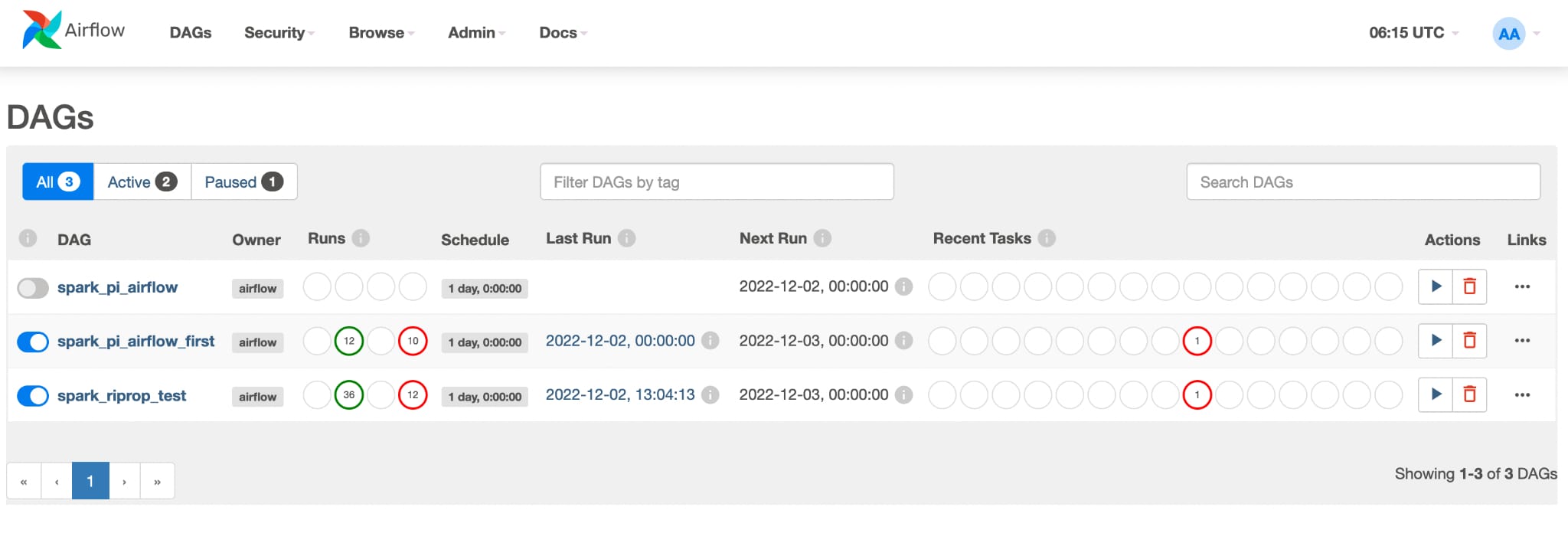
The same can be verified from seeing the spark driver pod log using the command shared previously (kubectl -n spark-jobs logs -f spark-pi-driver).
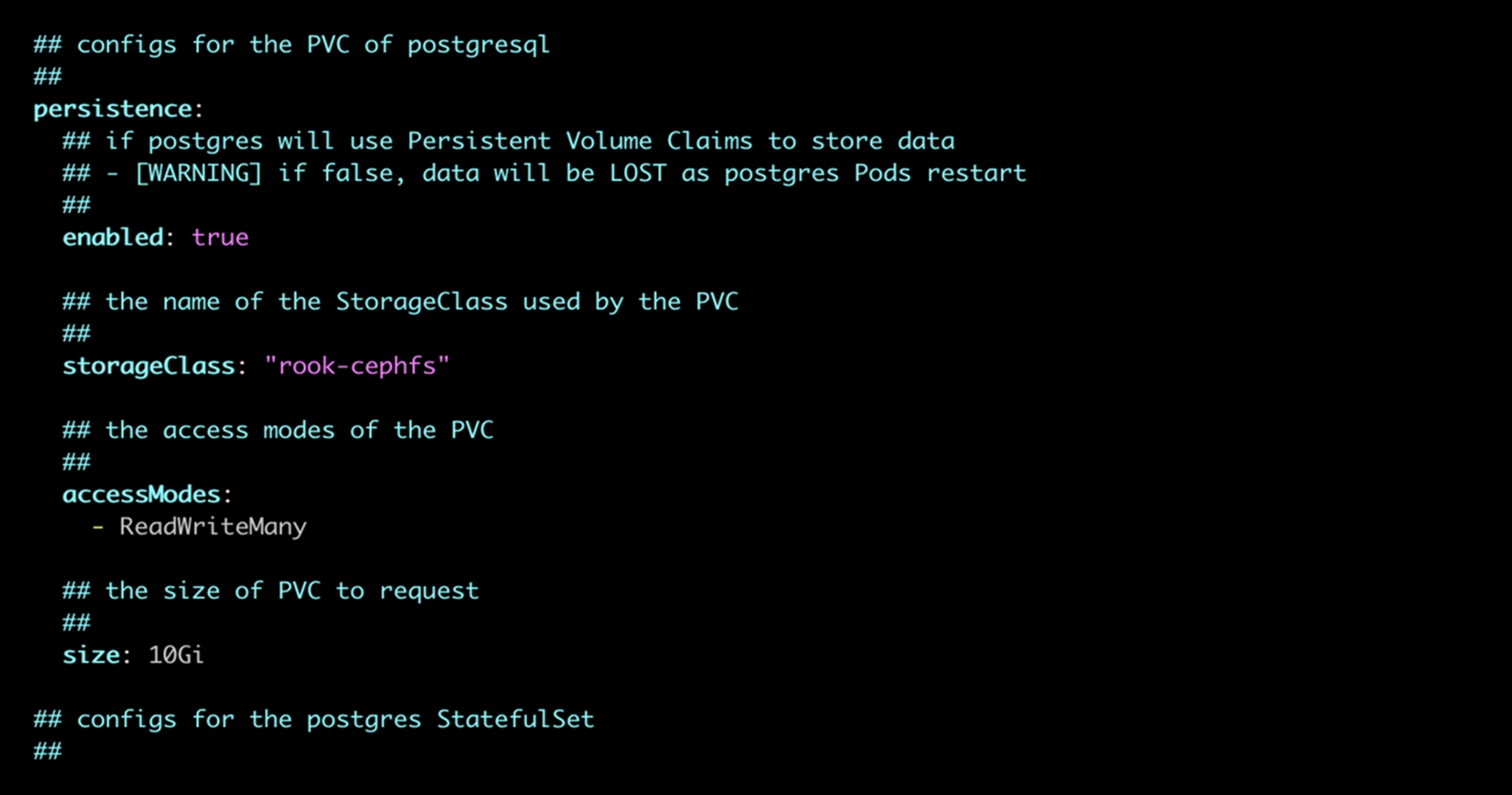
At this point, the development process can start for running the Spark application. It is recommended to add a PVC for PostGres to preserve all the data in Airflow. Additionally, as per requirements or specific needs, consider adding PVC to all necessary pods, including the Spark application.
3e. Steps to add PVC for PostGres:-
- For adding the PVC, set ‘enabled to true’ under the persistence section
- Add storageClass (in case of using rook-cephfs)
- Add the size according to requirement
Conclusion
It is evident that Kubernetes allows testing of the system without having to reserve or dedicate hardware to the purpose and this facilitates and makes it much more comfortable trying new things, ways of working, new features, different configurations, etc. Spark is a powerful data analytics platform that empowers you to build and serve machine learning applications with ease. With Kubernetes, the containerized hosting model of applications can be automated, thanks to its scheduler and APIs that optimize resource usage across hosted applications in clusters. Together, Spark and Kubernetes offer the ultimate solution for ML experts, providing the best of both worlds. By setting up Spark instances into K8s clusters,enterprises can unlock a seamless and well-documented process that streamlines data workflows.
About the author
Chandan Pandey is DataOps Lead Engineer at Sigmoid. He has 7+ years of providing end-to-end solutions for scalable, highly available, and secure cloud environments using platforms like AWS, GCP & Azure. He specializes in leveraging the most cutting-edge tools and technologies to build secure and robust architectures, and in deploying and managing containerized applications.
Ganesh Kumar Singh is DataOps II Engineer at Sigmoid. He specializes in development, deployment and maintenance of cloud-based applications with extensive hands-on experience in automation, scripting, source control management, and configuration management using a variety of platforms and tools for more than 4 years.


