Migrating from Azure Data and AI Stack to Microsoft Fabric: A practical overview
Reading Time: 9 minutes

As the landscape of data platforms continues to evolve, Microsoft has introduced Microsoft Fabric as a comprehensive solution for data integration, analytics, and AI. As a primer, refer to our blog on Implementing Data Mesh on Microsoft Fabric: A Step-by-Step Guide
The question of migrating to Fabric may arise for organizations already invested in Microsoft Azure’s Data and AI stack. In this blog, we’ll walk through considerations and essential steps for migrating from Azure’s existing services to Fabric, leveraging the latest advancements in data Fabric to streamline data operations.
Key azure workloads and migration to fabric equivalents
The question of which Azure workloads are amenable to MS Fabric migration is addressed using the below criteria:
Migration amenability score |
|
|
|
Lift and shift of existing artifacts with minimal manual effort. Decommission existing workloads post migration. |
|
|
Lift and Shift possible for some but not all artifacts. Decommission existing workloads post migration. |
|
|
Artifacts have to be recreated / recoded in Fabric. Decommission existing workloads post migration. |
|
|
No equivalent Fabric capability. Integration is feasible at present |
|
|
No equivalent Fabric capability. Integration is not feasible at present. |
Services with a score of 5 indicate a near-seamless migration, while a score of 3 suggests the need for more involved processes, such as data restructuring or schema changes.
Migration amenability assessment
Capability
Data Lake Storage
Amenability Score
Native Azure Feature
- ADLS Gen2
Fabric Feature
- OneLake – on ADLS Gen2
Short term – Data movement from ADLS to Fabric is not necessary. Creating ‘Shortcuts’ can provide access to ADLS Long Term – Phased data migration is required to decommission PaaS and get the full benefits of SaaS model.
Data Warehouses / Data Marts – SQL Workloads
Amenability Score
Native Azure Feature
- Serverless and Dedicated SQL Pools
Fabric Feature
- Synapse Data Warehouse
Migrating from Synapse Analytics Dedicated SQL Pools requires robust planning and migration methodology. For small data marts (GBs), options are available to migrate using Fabric Data Factory Copy Wizard. For large data warehouses (TBs), convert schemas to Fabric with Copy Wizard, then export data to Lakehouse using CETAS, then ingest this data into Fabric Warehouse using COPY INTO or Fabric Data Factory activities.
Lakehouse
Amenability Score
Native Azure Feature
- Synapse Delta Lake
Fabric Feature
- Synapse Data Lakehouse
Structured / Semi-structured data in any other format has to be converted to Delta format and stored in OneLake to make it queryable by SQL or Spark compute engines.
Big Data Engineering
Amenability Score
Native Azure Feature
- Azure Synapse Spark
Fabric Feature
- Fabric Spark
Migrating from Azure Synapse Spark requires robust planning and migration methodology. Spark Pools, Spark Configurations, and Spark Libraries have to be manually re-created in Fabric Notebooks. Spark Job definitions and Hive Metastore can be exported from Azure Synapse and imported into Fabric. Time to spin up Spark is significantly reduced in Fabric.
Data streaming
Amenability Score
Native Azure Feature
- Stream Ingestion – Event Hubs, IoT Hubs, Event Grids
- Stream Storage – Event / IoT Hubs
- Stream Processing – Azure Stream Analytics
- Destination – Azure Data Explorer / Azure CosmosDB / ADLS Gen2
Fabric Feature
- Stream Ingestion – No native service. Use Azure Event Hub / IoT Hub
- Stream Storage – No native service. Use Azure Event Hub / IoT Hub
- Stream Processing – Event stream
- Destination – Event house > KQL datasets,
No direct path for migration from Azure PaaS to Fabric. Use cases will have to be recreated using Fabric services. Additional services in Fabric include: Connectors to Amazon Kinesis, Google Pub/sub. Native integration with CDC for Azure SQL DBs, Cosmos DB Data profiling, anomaly detection, and forecasting available. Integration with PBI or TP tools like Kibana, Grafana, etc Reflex items through Data Activator enable downstream actions in other services Real-time hub provides a catalog
Data Pipelines Orchestration
Amenability Score
Native Azure Feature
- Azure Data Factory – Mapping Data flow (No/Low code)
- ADF Pipelines (Custom code)Power BI – Dataflow Gen1
Fabric Feature
- Data Factory – Dataflows Gen2 (Low Code)
- Data Pipelines (Custom code)
- Missing- SSIS, CI/CD
Short term – Existing ADF pipelines can write to OneLake. Dataflow Gen 1 queries can be exported as PQT files and imported into Dataflow Gen2. Copy-pasting queries is another option Long Term – Mapping flows to be redone in Dataflow Gen2 or converted to Spark code for Fabric. Upgrade experience from existing ADF pipelines to Fabric is set to release.
NoSQL Data Stores
Amenability Score
Native Azure Feature
- Azure Cosmos DB
Fabric Feature
- No Equivalent Data store
Mirroring option is available for Azure CosmosDB, Azure SQL Database, and Snowflake. This converts data to Delta format and incrementally ingests new data in near real-time. Mirroring is free of cost for computing and is used to replicate your Cosmos DB data into Fabric OneLake. Storage in OneLake is free of cost based on certain conditions. For more information, see OneLake pricing for mirroring. The compute usage for querying data via SQL, Power BI or, Spark is still charged based on the Fabric Capacity.
ML Development
Amenability Score
Native Azure Feature
- Azure Machine Learning Studio
Fabric Feature
- Fabric Notebooks
Notebooks can be migrated without much refactoring AzureML pipelines are not available. Data Factory pipelines are alternate and have to be created from scratch (unless they are notebook-based) Data asset management available in AzureML SDK is not available in Fabric Fabric provides an MLFlow endpoint eliminating the need to create an instance of Azure Machine Learning to register ML models/log experiments
MLOps
Amenability Score
Native Azure Feature
- Azure Machine Learning MLOps
Fabric Feature
- NA
Governance features are not available currently: Azure Machine Learning data assets (help you track, profile, and version data), Model interpretability (allows you to explain your models, meet regulatory compliance, and understand how models arrive at a result for a given input), Azure Machine Learning Job history (stores a snapshot of the code, data, and computes used to train a model), Azure Machine Learning model registry (captures all the metadata associated with your model) Integration with Azure allows you to act on events, such as model registration, deployment, data drift, and training (job) events, in the machine learning lifecycle.
Analytics App
Amenability Score
Native Azure Feature
- Power BI
Fabric Feature
- Power BI
Selection of the right capacity based on current usage is required. All artifacts can move seamlessly to Fabric
Data Governance
Amenability Score
Native Azure Feature
- MS Purview
Fabric Feature
- MS Purview Hub (preview)
Purview can connect to Fabric data estate and create catalogs automatically.
Data Sharing
Amenability Score
Native Azure Feature
- Azure Data Share
Fabric Feature
- External Data Sharing -only between Fabric tenants
- Clean room – no capability
Since there is no equivalent capability in Fabric, users have to leverage Azure Data Share.
DevOps
Amenability Score
Native Azure Feature
- Azure DevOps & GitHub
Fabric Feature
- Azure DevOps & GitHub
Github or Azure DevOps deployed on Azure can be reused.
Configurability
Amenability Score
Native Azure Feature
- Configure the storage and compute required for each workload
Fabric Feature
- SKU’s offer choice of compute power in terms of Capacity Units
No direct mapping from Azure to Fabric configurations is available as of today. We suggest starting with ‘Trial’ SKU and adjusting upwards as you migrate more workloads to Fabric.
Pricing
Amenability Score
Native Azure Feature
- Sizing – Different for each component
- Charging – Usage based, different tiers for each component
Fabric Feature
- Sizing – SKU (Capacity) based
- Charging – monthly committed spend
No direct mapping from Azure sizing to Fabric capacity units is available as of today. Consider starting with an SKU where monthly costs are in the ballpark of your current Azure spends.
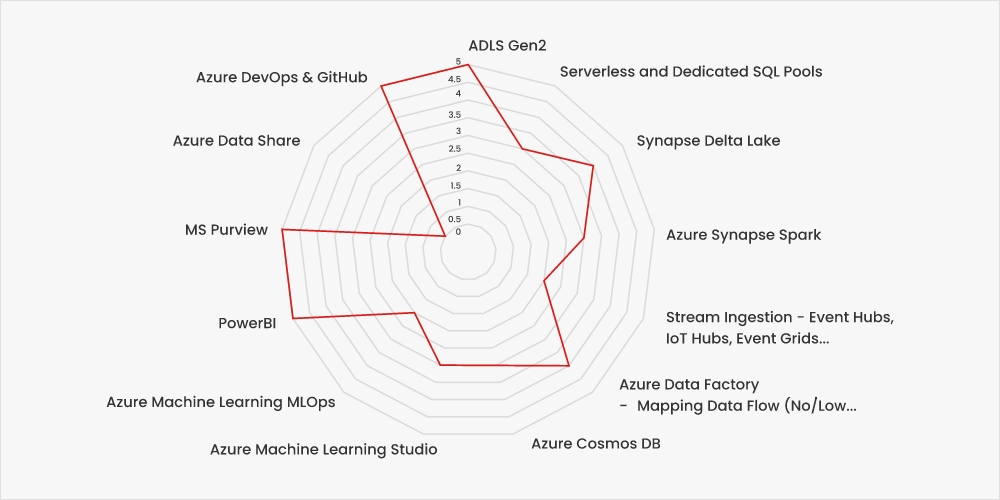
Fig. Migration Ameanibility score
As Fabric continues to evolve and add more capabilities, we expect a more complete mapping of capabilities to the native Azure stack to allow complete migration to the SaaS model.
For workloads with scores of 1 or 2, we recommend a wait-and-watch approach as Fabric adds capabilities over the next few quarters.
For workloads with scores of 3, 4, or 5, enterprises can consider undertaking PoCs to test capabilities before evolving a concrete migration plan.
Capability mapping to other CSP data and analytics stacks
For enterprises already invested in other hyperscalers, a migration to Fabric is likely to involve a relook at their data, analytics, and AI strategy. The paradigm shift from the PaaS to SaaS model offers a compelling reason to consider such a move. The below table provides a mapping of capabilities between Fabric and other stacks as of today.
Note: The migration amenability is not as relevant in this context, hence omitted
| Capability | MS Fabric | AWS | GCP |
|---|---|---|---|
| Data Lake Storage | ADLS Gen2 (no configuration access) | AWS S3 | Google Cloud Storage |
| Data Warehouses / Data Marts – SQL Workloads | Synapse Data Warehouse | Amazon Redshift,Amazon Athena | BigQuery |
| Lakehouse | Synapse Data Lakehouse | Combination of AWS S3, Amazon Redshift with Lake Formation | BigLake |
| Big Data Engineering | Fabric Spark | Amazon EMR (PaaS or Serverless),Amazon Athena | Dataproc |
| Data streaming | Stream Ingestion – No native service. Use Azure Event Hub / IoT Hub Stream Storage – No native service. Use Azure Event Hub / IoT Hub Stream Processing – Event stream Destination – Event house > KQL datasets, |
Stream Ingestion – AWS IoT, Kinesis Agent Stream Storage – Kinesis Data Streams, Amazon MSK, Apache Kafka Stream Processing – Amazon EMR, AWS Glue Destination – Amazon DynamoDB, Amazon OperSearch Service |
Stream Ingestion – Pub/Sub Stream Storage – Pub/Sub Stream processing – Dataflow, Cloud functions Destination – BigQuery, Cloud Datastore, Cloud Storage Cloud IoT Core Device SDK, |
| Data Pipelines Orchestration | Data Factory Dataflows Gen2 (Low Code) Data Pipelines (Custom code) Missing- SSIS, CI/CD |
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) , AWS Step Functions |
Cloud Composer,Cloud Workflows |
| NoSQL Data Stores | No Equivalent Data store | Amazon DynamoDB (Key-value),Amazon DocumentDB (Document),Amazon Neptune (Graph),Amazon Keyspaces (Column) | Cloud Datastore (Key-value),Cloud Firestore (Document),Cloud Neo4J (Graph),Cloud Cassandra (Column) |
| ML Development | Fabric Notebooks | Amazon SageMaker | Vertex AI |
| MLOps | MLFlow Integration NA | Amazon SageMaker MLOps | Vertex AI MLOps |
| Analytics App | Power BI | Amazon QuickSight | Looker |
| Data Governance | MS Purview Hub (preview) | Amazon Data Zone AWS Lake Formation, AWS Glue Catalog | Dataplex |
| DevOps | Azure DevOps & GitHub | AWS CodeCommit, AWS CodeBuild, AWS CodePipeline | Cloud Source Repositories, Cloud Build, Cloud Deploy |
Migration methodology
For Azure workloads with amenability of >=3 and for workloads on other CSPs, robust planning is key to a successful migration. Sigmoid has helped several clients through migrations of their data, analytics, and AI workloads. We cover the critical elements of a migration plan below.
Step 1: Evaluate current workloads
Before starting the migration process, it’s crucial to evaluate your current workloads running on Azure / other CSP services. Determine which services are most critical to your operations and map them to the corresponding Fabric services using the table above.
A plot of the business criticality vs. migration amenability can help prioritize candidate workloads for migration. The workloads towards the top right are the most suitable for migration. A sample of such a prioritization matrix is below. However, this has to be moderated by the upstream and downstream dependencies for each workload. For example, Power BI Reports & Dashboards Best Practices can simplify reports migration, but their effectiveness relies on the migration of DE Pipelines, Storage, and Semantic Data Models.
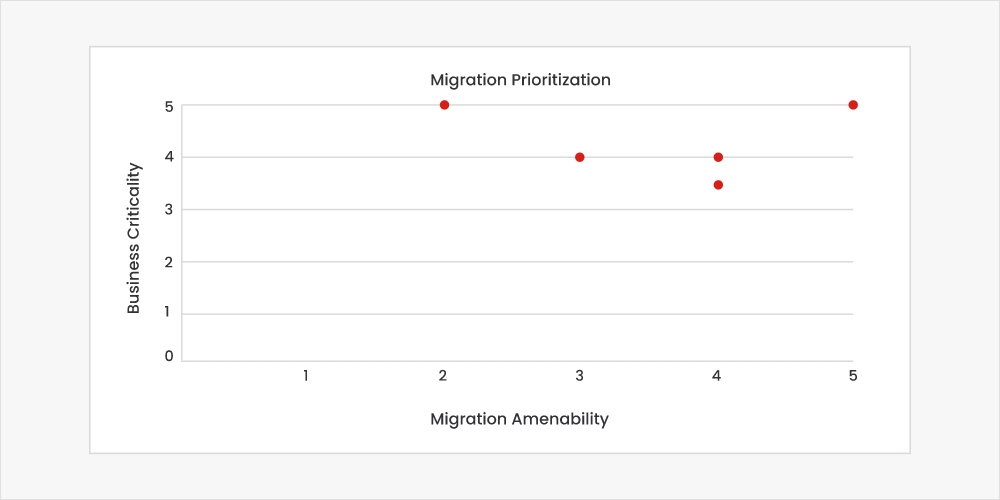
Fig. Sample prioritization framework
Step 2: Prepare for data migration
- Provision MS Fabric Capacity
- Prepare Environments and DevOps – Dev, Test, Production. Azure DevOps
- Detailed analysis of Existing workloads
- Architecture
- Schema
- Security
- Operational Dependencies
- PoC / MVP Plan
- Timelines
- Fabric capacity
- Tools & accelerators
- Test Plan and quality assurance
- Contingency plan
Step 3: Implement migration
For each service, there are specific migration strategies and considerations. For example,
- ADLS Gen2 / Delta Lake to Fabric: Leverage shortcuts to begin migrating data from Azure Data Lake Storage into Fabric. Ensure you have appropriate access control and configuration management.
Provision bronze, silver, and gold layers on Fabric to prepare for lift and shift of data from Azure / other CSPs. - Synapse Analytics to Fabric: Migration of analytics services like Serverless SQL or Dedicated SQL Pools requires thorough validation of queries, tables, and data models. Fabric’s Synapse Data Warehouse can support these workloads but may require additional configurations for performance optimization.
The typical activities to be executed include:
- Reverse engineer DDL, PL/QSL, ETL
- Build or copy reports, data models
- Identify workarounds for artifacts that cannot be migrated to Fabric at this point
- Configure security model & RBAC
- Perform thorough unit and integration testing
- Perform UAT
After completion of UAT,
- Promote code to production
- Execute historical data loads
- Enable incremental data loading pipelines and perform data quality checks
- Perform parallel run with existing env and perform reconciliation checks
- Support users to perform testing on new Fabric reports
- Cut-over to Fabric and provide hyper care support to business users
- Decommission existing workloads where feasible by design
Step 4: Post-migration optimization
Once migration is complete, ongoing optimization is necessary to ensure that you leverage the full capabilities of Microsoft Fabric. Fabric is designed to enhance data integration and standardization across data lakes and data warehouses, ensuring seamless operations and real-time analytics, so take time to:
- Monitor data integration and synchronization processes.
- Adjust access control policies to reflect the new environment.
- Observe capacity unit utilization and optimize SKU’s tier.
Conclusion
Migrating from Azure Data and AI stack or other CSPs to Microsoft Fabric requires a thoughtful, staged approach. By evaluating the amenability of different Azure services and understanding how they map to Fabric features, organizations can ensure a methodical transition. With the right planning, this migration can enhance operational efficiency and unlock new capabilities within the Fabric ecosystem.
About the author
Vinay Prabhu is the Director, Data Engineering at Sigmoid. He has over 10 years of experience across Azure, AWS data & analytics stacks. With his extensive knowledge and experience in data engineering and analytics projects, he helps enterprises in CPG, Manufacturing, and BFSI extract meaningful insights from data to drive informed decision-making.
References:
- Microsoft Fabric documentation
(https://learn.microsoft.com/en-us/fabric/) - Microsoft Fabric community
(https://community.fabric.microsoft.com/t5/Data-Science/Machine-learning-pipelines-in-Microsoft-Fabric/m-p/3818195#M161) - Microsoft Azure documentation
(https://learn.microsoft.com/en-us/azure/?product=analytics) - AWS documentation
(https://docs.aws.amazon.com/) - GCP documentation
(https://cloud.google.com/solutions/data-analytics-and-ai?hl=en)





