Outsmarting humans: An introduction to reinforcement learning
Reading Time: 4 minutes

The brain of a human child is spectacularly amazing. Even in any previously unknown situation, the brain makes a decision based on its primal knowledge. Depending on the outcome, it learns and remembers the most optimal choices to be taken in that particular scenario. On a high level, this process of learning can be understood as a ’trial and error’ process, where the brain tries to maximize the occurrence of positive outcomes.
Reinforcement Learning
Reinforced Learning works just like a child’s brain, that can remember each and every decision taken in given tasks. In Reinforcement Learning, the learner isn’t told which action to take, but is instead made to try and discover actions that would yield maximum reward. In the most interesting and challenging cases, actions may not only affect the immediate reward, but also impact the next situation and all subsequent rewards. These two characteristics: ‘trial and error search’ and ‘delayed reward’ are the most distinguishing features of reinforced learning.
Machines vs Humans
Many of us must have heard about the famous Alpha Go, built by Google using Reinforcement Learning. This machine has even beaten the world champion Lee Sudol in the abstract strategy board game of Go!
Elon Musk in a famous debate on artificial intelligence with Jack Ma, explained how machines are becoming smarter than humans. Reinforcement Learning is definitely one of the areas where machines have already proven their capability to outsmart humans.
The Video Games Analogy
Reinforcement Learning can be understood by an example of video games. A typical video game usually consists of:
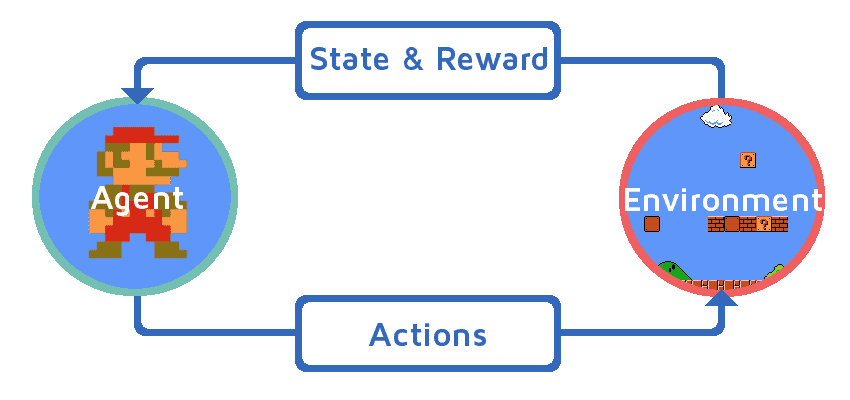
Fig: A Video Game Analogy of Reinforcement Learning
- An agent (player) who moves around doing stuff
- An environment that the agent exists in (map, room)
- An actionthat the agent takes (moves upward one space, sells cloak)
- A reward that the agent acquires (coins, killing other players)
- A statethat the agent currently exists in (on a particular square of a map, part of a room)
- A goal that the agent may have (level up, getting as many rewards as possible)
The agent basically runs through sequences of state-action pairs in the given environment, observing the rewards that result, to figure out the best path for the agent to take in order to reach the goal.
Rules of Reinforcement Learning
The Markov decision process lays the foundation stone for Reinforced Learning and formally describes an observable environment. There are two important parts of Reinforcement Learning:
Policy Learning: This is a function that maps a given state to probabilities of selecting each possible action from that state. In simple terms, it identifies the best probable set of actions an agent should take in order to maximize their reward. This policy is learnt by taking random decisions and then iterating backward (updating weights) once there is a positive or negative end result.
Value Functions (Q Learning): These are functions of states, or of state-action pairs, that estimate how good is it for an agent to be in a given state, or how good is it for the agent to perform a given action in a given state. Unlike Policy Learning, Q-Learning takes two inputs: state and action, and returns a value for each pair. If you’re at an intersection, Q-Learning will tell you the expected value of each action that your agent could take (left, right, etc.).
Applications of Reinforcement Learning:
There are numerous application areas of Reinforcement Learning. Starting from robotics and games to self-driving cars, Reinforcement Learning has found applications in many areas. Famous researchers in the likes of Andrew Ng, Andrej Karpathy and David Silverman are betting big on the future of deep Reinforced Learning.
Final Words
It seems till date that the idea of outsmarting humans in every field is farfetched. But the seed has been sown and companies like Google and Tesla have shown that if machines and humans work together, the future has many opportunities to offer. As far as Reinforcement Learning is concerned, we at Sigmoid are excited about its future and its game changing applications.
About the Author
Abhijeet is a Data Scientist at Sigmoid. He mainly works in the domain of Recommendation Engines, Time Series Forecasting, Reinforcement Learning, and Computer Vision.
Featured blogs







Featured blogs