GPT-3: All you need to know about the AI language model
Reading Time: 7 minutes

What is GPT-3?
The launch of Open AI’s third generation of the pre-trained language model, GPT-3 (Generative Pre-training Transformer) has got the data science fraternity buzzing with excitement!
The world of Language Models (LM) is quite fascinating. To give a brief introduction, these AI ML models learn the probabilities of a sequence of words that occur in a commonly spoken language (say, English) and predict the next possible word in that sequence. They are essential for numerous NLP tasks like:
- Language Translation
- Text Classification
- Sentiment Extraction
- Reading Comprehension
- Named Entity Recognition
- Question Answer Systems
- News Article Generation, etc
Artificial intelligence models in natural language and processing have become immensely popular since the release of BERT by Google, with a host of companies competing to build the next big thing in the NLP domain!
Did You Know How GPT-3 Was Trained?
Pre-training involves a deep neural network with a transformer architecture trained on a large corpus, divided into smaller units called tokens such that it can learn to predict the next token in a sequence of tokens with context. Fine-tuning involves further training of the pre-trained model for specific tasks or a range of tasks or domains, including translation, question-answering, text completion, etc. with labeled examples. For instance, to make GPT-3 good at translation, it’s fine-tuned on a dataset of translated sentences.
Open AI has been in the race for a long time now. The capabilities, features, and limitations of their latest edition, GPT-3, have been described in a detailed research paper. Its predecessor GPT-2 (released in Feb 2019) was trained on 40GB of text data and had 1.5 BN parameters. In comparison, GPT-3 training data size is huge and includes about 175 BN parameters, 10 times more than the next largest LM, the Turing NLG, developed by Microsoft with 17 BN parameters!
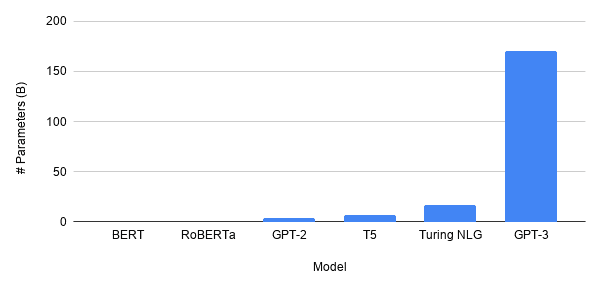
Fig-1: Comparison of all available language models (LMs) parameter wise
Maximize efficiency with Generative AI
Explore Sigmoid’s pre-built Generative AI solutions for use cases across marketing, customer experiences, and more!
GPT-3 is based on the concepts of transformer and attention similar to GPT-2. It has been trained on a large and variety of data like Common Crawl, webtexts, books, and Wikipedia, based on the tokens from each data. Prior to training the model, the average quality of the datasets have been improved in 3 steps.
The following table shows the training corpus of GPT-3:
| Datasets | Quantity (Tokens) | Weight in Training Mix | Epochs elapsed when training for 300 BN tokens |
|---|---|---|---|
| Common Crawl (filtered) | 410 BN | 60% | 0.44 |
| WebText2 | 19 BN | 22% | 2.90 |
| Books1 | 12 BN | 8% | 1.90 |
| Books2 | 55 BN | 8% | 0.43 |
| Wikipedia | 3 BN | 3% | 3.40 |
There are several GPT-3 examples and variants in terms of:
- Sizes (Parameters and Layers)
- Architectures
- Learning hyper-parameters (batch size in tokens and learning rate) ranging from 125 MN to 175 BN parameters
Did You Know?
The largest version of GPT-3 has 175 BN Parameters, 96 Attention Layers and 3.2 MN Batch Size
Here are the details of the different variants of GPT-3 model:
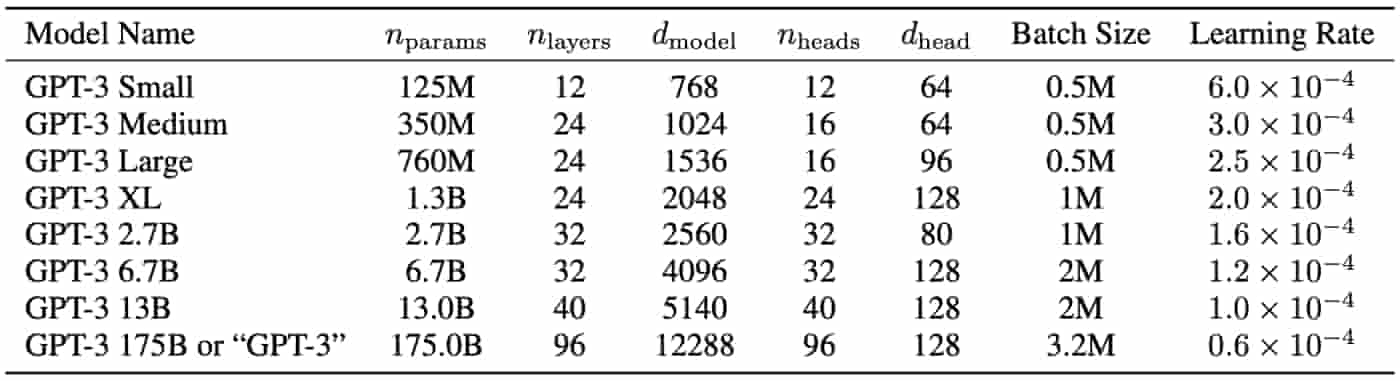
Fig-2: Details of variants of the GPT-3 model
What can it do?
Many of the NLP tasks discussed in this blog can be performed by GPT-3 without any gradient, parameter updates or fine tuning. This makes it a Task-Agnostic Model as it can perform tasks without any or very few prompts or examples or demonstrations called shots.
The following image displays a Zero / One / Few-Shot based task accuracy comparison for various GPT-3 model sizes (in terms of parameters) for a simple task to remove random symbols from a word with the number of in-context examples ranging between 10 to 100.
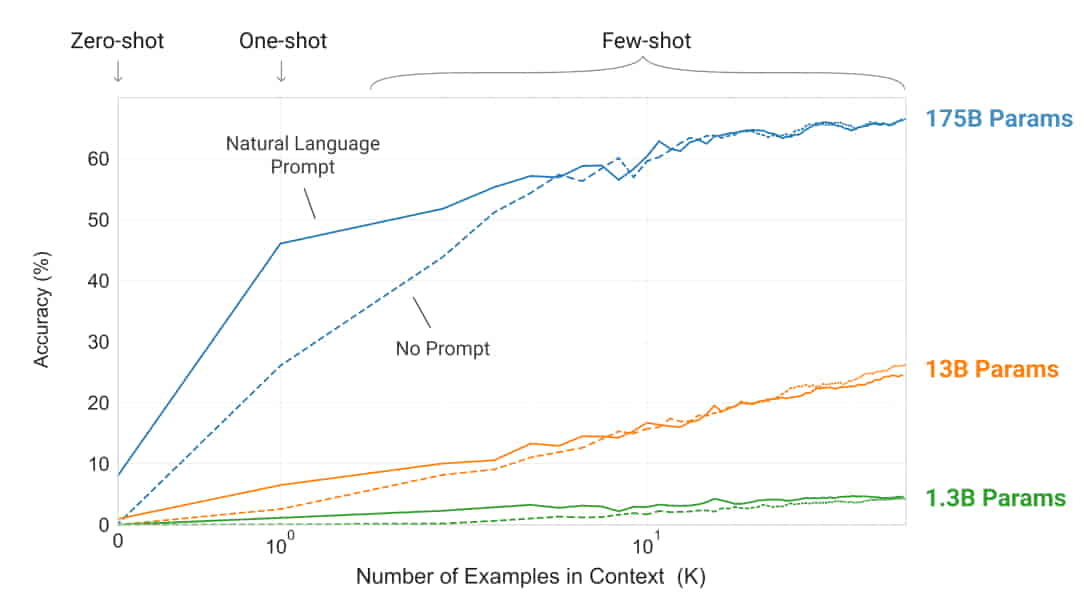
Fig-3: Zero / One / Few-Shot based task accuracy comparison for models of different sizes
The “Fake News” Conundrum
Earlier, the release of the largest model of GPT-2 was briefly stalled due to a controversial debate of it being capable of generating fake news. It was later published on Colab notebooks. In recent times, however, this has been quite common and the real news themselves have been hard to believe!
The fake news generated by GPT-3 has been so difficult to distinguish from the real ones, and in one of the experiments, the results show that only 50% of the fake news could actually be detected!
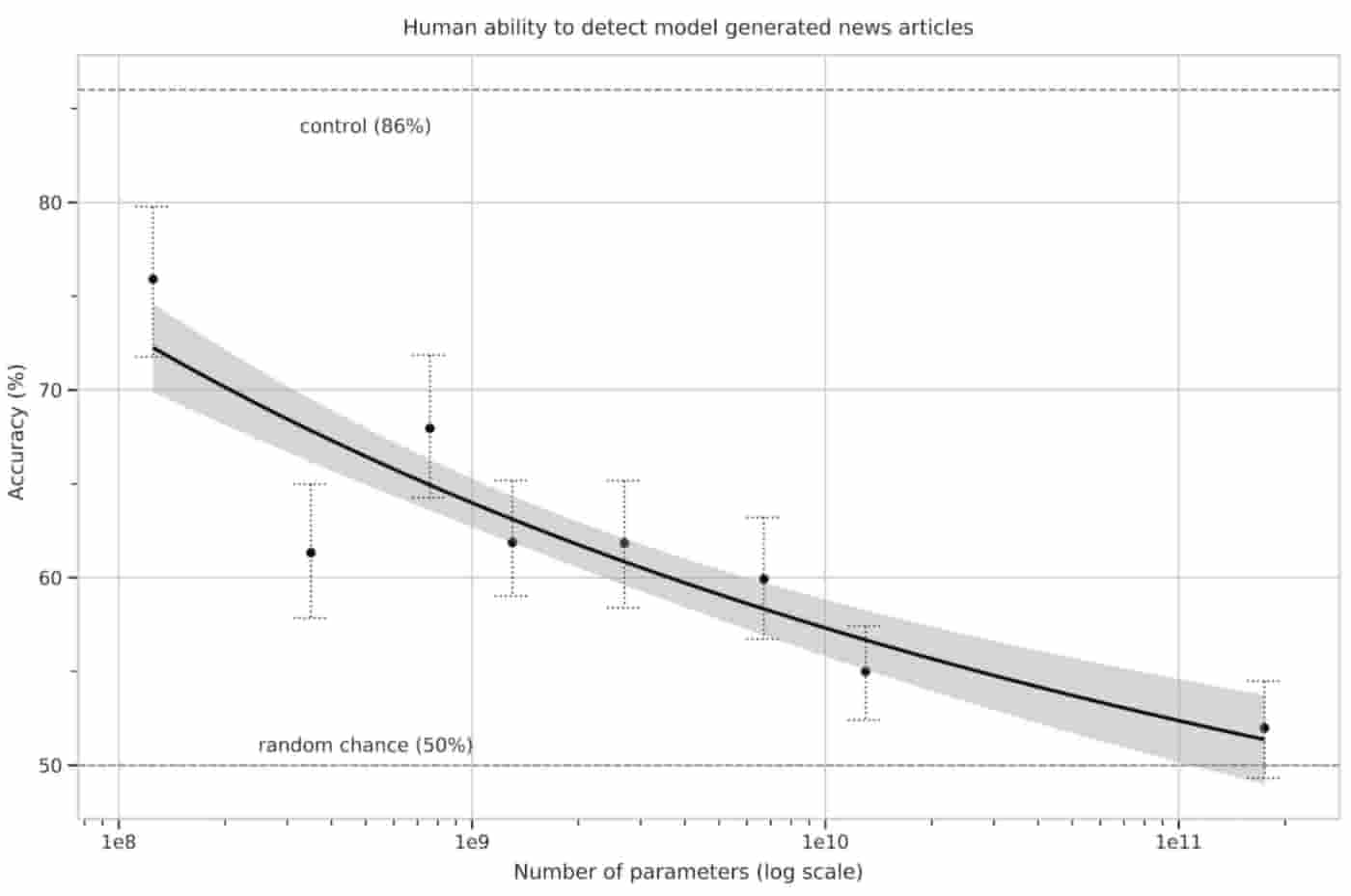
In a task to predict the last word of a sentence, GPT-3 outperformed the current SOTA (state of the art) algorithm by 8% with an accuracy score of 76% in a zero-shot setting. In the few-shots setting, it has achieved an accuracy score of 86.4%!
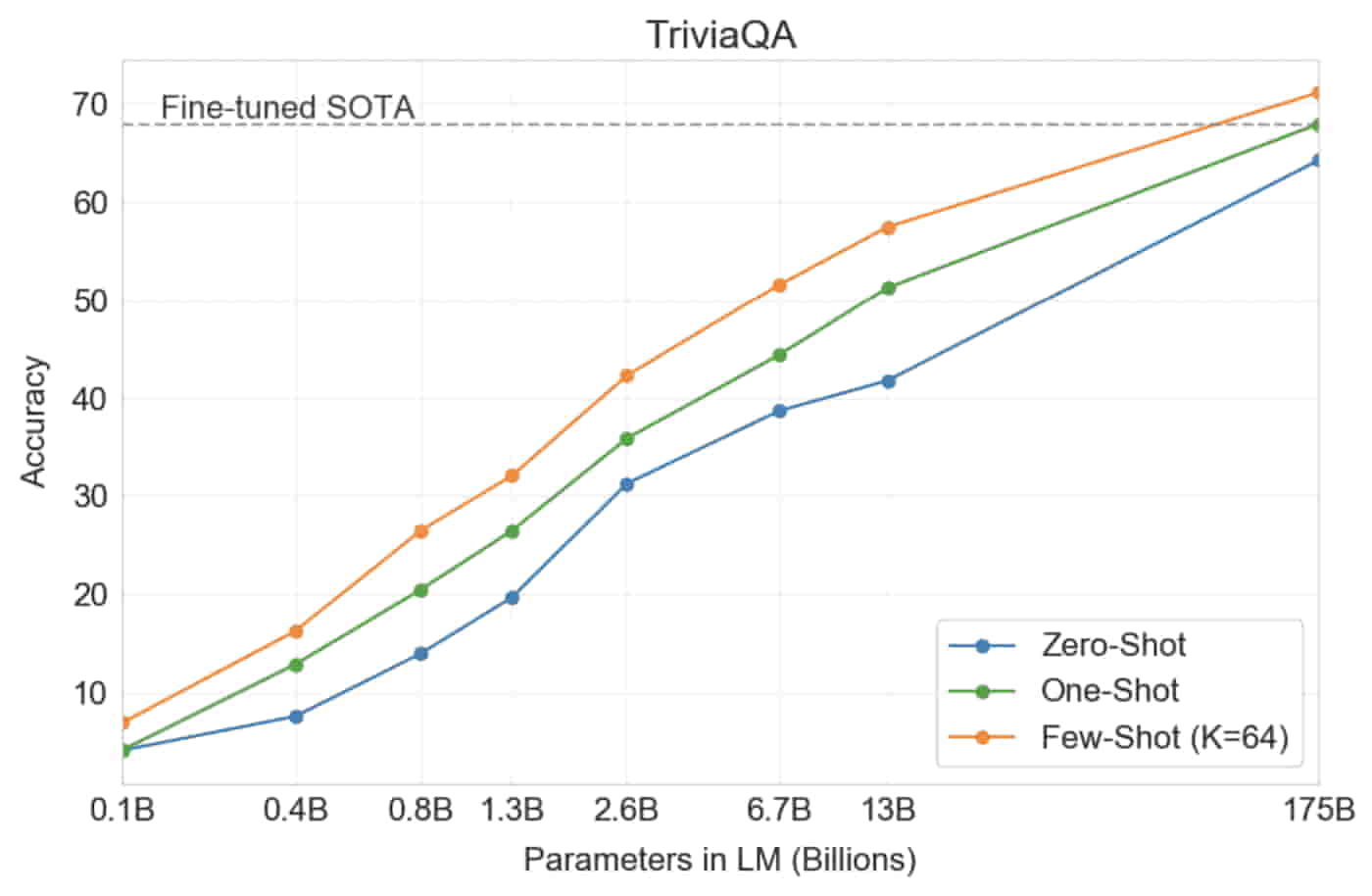
In a closed book question answering tasks, GPT-3 outperformed a fine-tuned SOTA that uses an Information Retrieval component in both one and a few-shot settings.
The GPT-3 API has been on the waiting list, but all the folks who could get a chance to try it shared their interesting findings and amazing results of this powerful model. Here are a few things that were observed while experimenting on the API’s interface called the Playground.
Summary of the Open AI GPT-3 API Playground:
-
Settings and Presets:
Upon clicking the settings icon, one can configure various parameters like the text length, temperature (from low/boring to standard to chaotic/creative), start and stop generated text etc. And there are multiple presets to choose and play around with like Chat, Q&A, Parsing Unstructured Data, Summarize for a 2nd grader
- Chat:
The chat preset looks more like a chatbot where you can set the character of the AI as friendly, creative, clever and helpful mode which provides informative answers in a very polite manner whereas if you set the character of the AI to brutal it responds exactly as the character suggests! - Q&A:
Question answering needs some training before it starts answering our questions and people did not have any complaints with the kind of answers received. - Parsing Unstructured Data:
This is an interesting preset of the model which can comprehend and extract structured information from the unstructured text - Summarize for 2nd Grader:
This preset shows another level of text compression by rephrasing the difficult sentences and concepts into simpler words and sentences that can be easily understood by a kid
- Chat:
-
Multilingual text processing:
GPT-3 can handle languages other than English better than GPT-2. People have tried tasks in various GPT-3 supported languages such as German, Russian and Japanese. It did perform well and was very much ready for multilingual text processing.
- Text Generation:
It can generate poems on demand that too in a particular style if required, can write stories and essays with some fine-tuning even in other languages. - Code Generation:
People have claimed that this API can generate code with a minimum of prompts.
Above are a few of the GPT-3 examples that are taking AI language model development research by stride.
This is how the AI model interface looks like. (Below image shows the Q&A preset):
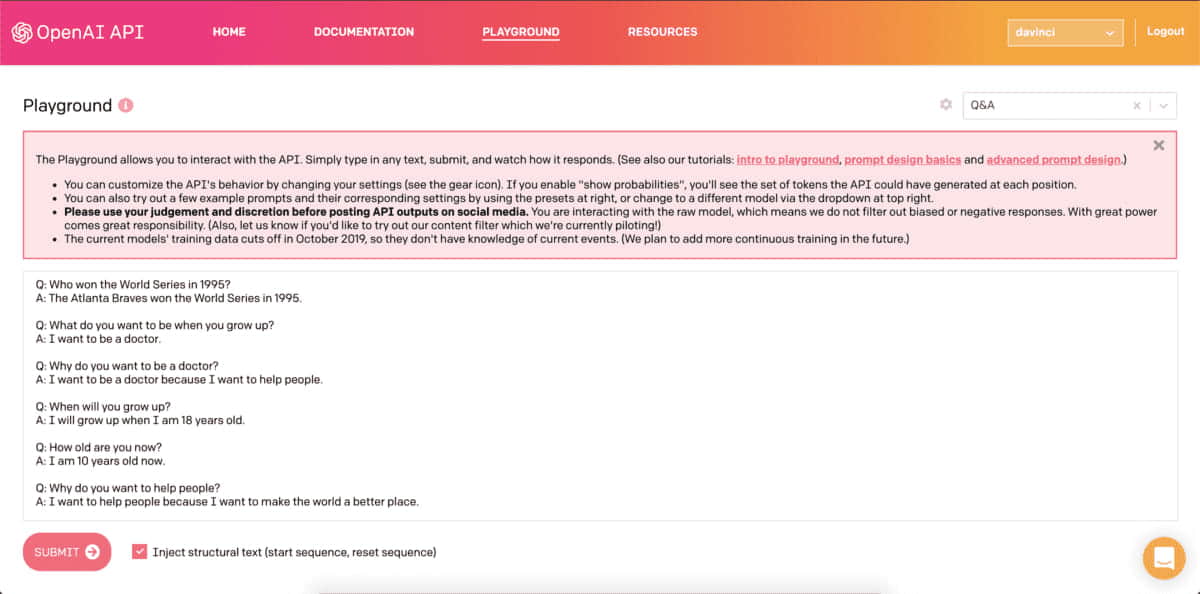
Fig-6: Preview of the AI Playground page for a Q&A preset
How can we use it?
Unlike a lot of language models, GPT-3 does not need Transfer Learning, where the model is fine-tuned on task specific data sets for specific tasks. The author of a research paper on GPT-3 mentions the following advantages of having a task-agnostic model:
- Collecting task-specific data is difficult
- Fine-tuning might yield out-of-distribution performance
- Need for an adaptable NLP system similar to humans, which can understand the natural language (English) and perform tasks with few or no prompts
The applications of GPT-3 are in context learning, where a model is fed with a task/prompt/shot or an example and it responds to it on the basis of the skills and pattern recognition abilities that were learned during the fine-tuning process.
Despite its tremendous usability, the huge model size is the biggest factor hindering the usage for most people, except those with available resources. However, there are discussions in the fraternity that distillation might come to the rescue!
What are the limitations?
The Open AI founder himself said that “GPT-3 has weaknesses and it makes silly mistakes”. It is weak in the segment of sentence comparison where it has to see the usage of a word in 2 different sentences.
As per the researchers, it still faces some problems in the following tasks:
- Repetitions
- Coherence loss
- Contradictions
- Drawing real conclusions
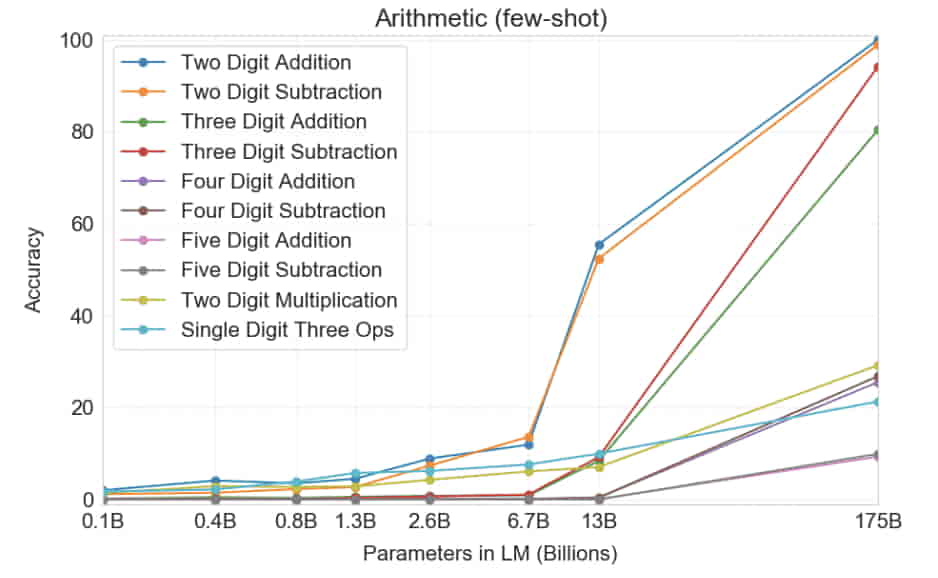
- Multiple digit additions and subtractions
Conclusion
It is great to have an NLP system that doesn’t require large amounts of custom-task-specific datasets and custom-model architecture to solve specific NLP tasks. The experiments conducted show its power, potential, and impact on the future of NLP advancement.
GPT-3 is a great example of how far AI model development has come. Even though GPT-3 doesn’t do well on everything so far and the size makes it difficult to be used by everyone, this is just the beginning of a lot of new improvements to come in the field of NLP!
References
- GPT-3 paper: https://arxiv.org/pdf/2005.14165.pdf
Images are picked from this paper. - GPT-3 Github page: https://github.com/openai/gpt-3
- Blog on GPT-2: https://openai.com/blog/better-language-models/
- Paper about the concepts of transformers and attention: https://arxiv.org/abs/1706.03762
- Link to the GPT-3 API: https://beta.openai.com/
- Paper on Distillation in Neural Networks: https://arxiv.org/abs/1503.02531
About the Author
Bhaskar Ammu is a Senior Data Scientist at Sigmoid. He specializes in designing data science solutions for clients, building database architectures and managing projects and teams.
Check how you can leverage our Data Science services to identify business problems and enable business transformation.





