Fault tolerant streaming workflows with Apache Mesos
Reading Time: 5 minutes

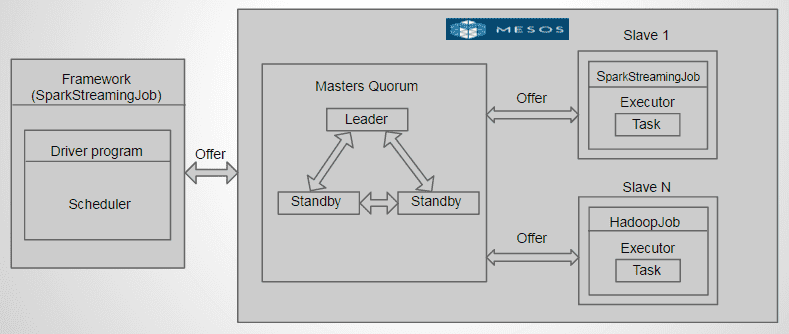
Mesos High Availability Cluster
Apache Mesos is a high availability cluster operating system as it has several masters, with one Leader. The other (standby) masters serve as backup in case the leader master fails. Zookeeper elects the master nodes and handles the failures.
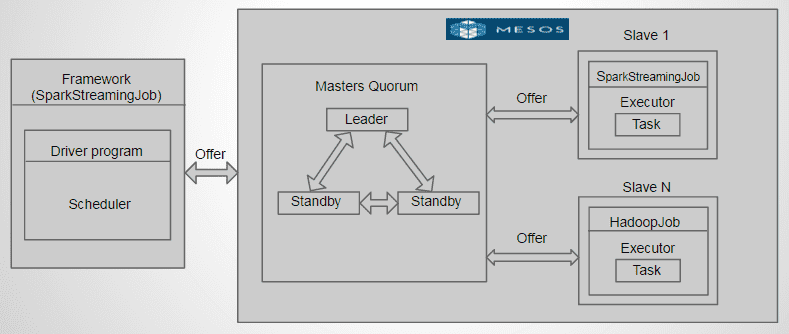
Mesos is framework independent and can intelligently schedule and run Spark, Hadoop, and other frameworks concurrently on the same cluster.
Before diving deep into how fault tolerance streaming workflows can be created with Apache Mesos, we will have a quick overview of Spark and Spark Streaming.
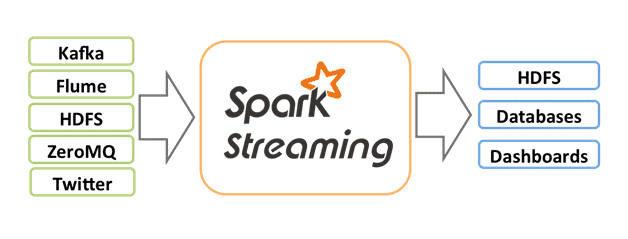
Spark powers a stack of frameworks including Spark SQL, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
RDDs
Resilient Distributed Datasets (RDDs) are a Big collection of data which are Immutable (can’t be changed once created), Distributed (across the cluster),Lazily evaluated (won’t do anything unless action is triggered.), Type Inferred (the compiler will figure out the object type), Cacheable (can load whole dataset into memory).
Many big-data applications viz., monitoring systems, alert systems, computing systems to name a few, need to process large data streams in near-real time. Spark Streaming can process large chunks of data, runs streaming computation as a series of small, batch jobs. In Spark Streaming, the incoming data is split into small batches of time interval (200ms by default) and Spark treats each batch data as a RDD and processes them using RDD operation, which are returned in batches after processing.
Spark Streaming over a HA Mesos Cluster
To use Mesos from Spark, you need a Spark binary package available in a place accessible (http/s3/hdfs) by Mesos, and a Spark driver program configured to connect to Mesos.
Configuring the driver program to connect to Mesos,
val sconf = new SparkConf()
.setMaster(“mesos://zk://10.121.93.241:2181,10.181.2.12:2181,10.107.48.112:2181/mesos”)
.setAppName(“MyStreamingApp”)
.set(“spark.executor.uri”,”hdfs://Sigmoid/executors/spark-1.3.0-bin-hadoop2.4.tgz”)
.set(“spark.mesos.coarse”, “true”)
.set(“spark.cores.max”, “30”)
.set(“spark.executor.memory”, “10g”)
val sc = new SparkContext(sconf)
val ssc = new StreamingContext(sc, Seconds(1))
Failure in simple streaming pipeline
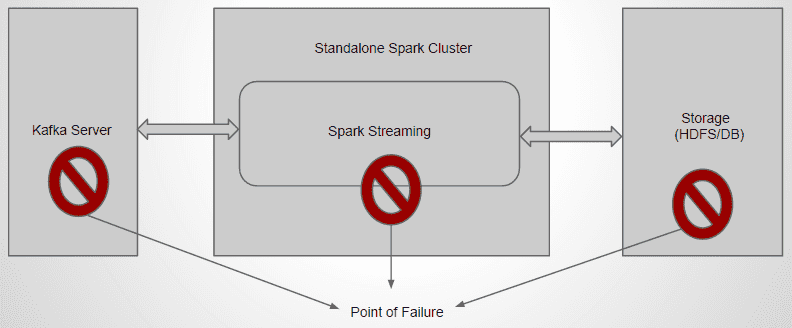
With a simple spark streaming pipeline as shown in the figure, there are certain failure scenarios that may occur. By default, Kafka and HDFS are configured in high-availability mode, we will be focusing on Spark streaming fault tolerance.
Real-time stream processing systems must be operational 24/7, which requires them to recover from all kinds of failures in the system.
- Spark and its RDD abstraction is designed to seamlessly handle failures of any worker nodes in the cluster
- In Streaming, driver failure can be recovered with checkpointing application state.
- Write Ahead Logs (WAL) & Acknowledgements can ensure zero data loss
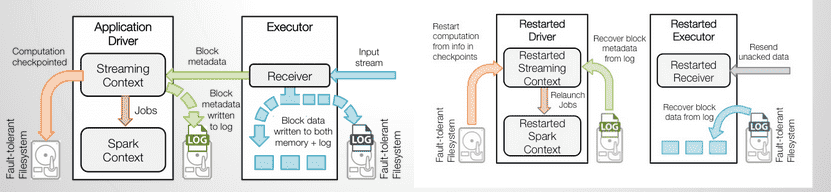
This image on right represents the processing of the received data in a fault tolerant system. When a Spark Streaming application starts (i.e., the driver starts), the associated StreamingContext (starting point of all streaming functionality) uses the SparkContext to launch Receivers as long running tasks, the receivers receive data from source systems like Kafka, flume etc These Receivers receive and buffers the streaming data into executors memory for processing.
In this fault tolerant file system the streaming data is checkpointed to another set of files periodically.
To ensure fault tolerance, when the failed driver restarts, the checkpointed data along with data from WAL is used to restart the driver, receivers and the contexts.
Simple Fault-tolerant Streaming Infra
Spark Streaming cluster and storage system are placed in Mesos cluster but the source systems like Kafka are out of the Mesos as the source can be from anywhere. So by having the Spark streaming in Mesos, even if a driver fails, there are standby drivers which takes care of the streaming process and thereby ensures fault tolerance.
Goal: Receive & process data at 1M events/sec
Understanding the bottlenecks:
- Network : 1Gbps
- # Cores/Slave : 4
- DISK IO : 100MB/S on SSD
Choosing the correct # Resources
- Since single slave can handle up to 100MB/S network and disk IO, a minimum of 6 slaves could take me to ~600MB/S
Scaling the pipeline
One way to obtain high throughput is to launch more receivers on machines, and it will let you consume more data at once. There are other techniques like, setting up custom add-ons on top of mesos like Marathon to throw more machines (scale up and down the cluster automatically). Before scaling any pipeline, one should always know their goals and the limitations on the available resources. So in a basic data-center all machines these days are equipped with around 4 cores of CPU, 1Gbit network card, and 100MB/S SSD Storage, if you say you want to process around 1Million events per second (600bytes each), then you will be needing like a minimum of 6 machines to get to that scale, since each of the machines can handle around 100MB/S in terms of network and DISK I/O.
About the Author
Akhil was a Software Developer at Sigmoid focuses on distributed computing, big data analytics, scaling and optimising performance.





