Implementing data products and Data Mesh on Microsoft Fabric for AI-powered analytics
Reading Time: 8 minutes

Microsoft Fabric is an end-to-end analytics and data platform designed to unify various data services into a single, cohesive environment. In this blog post, we explore the capabilities of this platform, understand what is a data mesh architecture and look at how it aligns with the key principles of a Data Mesh architecture and how it enables AI-powered analytics at scale.
Fabric’s SaaS model promises to simplify setup and management and offers automatic integration and optimization, thus reducing the complexity and cost of managing multiple services on a ‘traditional’ Azure-based data and analytics architecture. The focus therefore is likely to shift from managing cloud services to data and analytics assets. It would be possible to tailor experiences for different organizational roles (data engineers, data analysts, business users), ensuring that each team member has the tools they need to be effective. With Copilot integration, Fabric also infuses AI into everyday workflows, helping data engineers, analysts, and business users accelerate productivity and insight generation.
Key capabilities include:
- Data Engineering: Fabric provides robust tools for data movement, processing, and transformation, enabling seamless data integration for downstream analytics and AI applications.
- Data Factory: This capability allows for efficient data ingestion and orchestration, supporting complex data workflows and pipelines.
- Real-Time Analytics: It offers real-time event routing and analytics, ensuring timely insights and decision-making based on live data streams.
- Data Science: Fabric integrates advanced data science tools, facilitating machine learning model development, training, and deployment within the same platform
- Data Warehouse: Microsoft Fabric architecture includes a scalable data warehousing solution, centralizing data storage and enabling high-performance querying and reporting, with AI-driven recommendations through Copilot.
- Data Lakehouse: MS Fabric’s Lakehouse capability seamlessly integrates data lakes and data warehouses, enabling unified data management and analytics.
Key technical features underpinning the above capabilities
- OneLake: Perhaps the single most important feature that differentiates Fabric from preceding MS data offerings. All data is stored in Delta format (with Microsoft’s optimization algorithms on top). By adopting OneLake as the store (ADLS Gen2 behind the scenes) and delta as the common format for all workloads, Microsoft offers customers a data stack that’s unified at the most fundamental level. A single copy of the data in OneLake can directly power all the workloads to process/query data that were written by any of the other compute engines (T-SQL, Spark). Data objects are either
- Files – Object storage, raw files, reference files etc. not needed in tabular format
- Tables – Managed Delta Tables created through Spark or T-SQL
- Evenstream and KQL Database enable ingestion of streaming data which can be seamlessly integrated with One Lake and Power BI to enable real-time insights
- Fabric SQL Engine is designed to operate efficiently over any OneLake artifact, providing high performance for queries across data warehouses, lakehouses, and mirrored databases.
- Microsoft Purview integration provides a unified view of an organization’s data landscape. Metadata is automatically captured and can be viewed in Purview Data Catalog facilitating easy discovery, enhanced data lineage, and auditing capabilities.
- Azure ML Integration enables read and write back data to OneLake thus reducing the time to develop and test new models. Azure AI Studio’s Large Language Models (LLMs) can be enhanced through RAG by leveraging integration with OneLake.
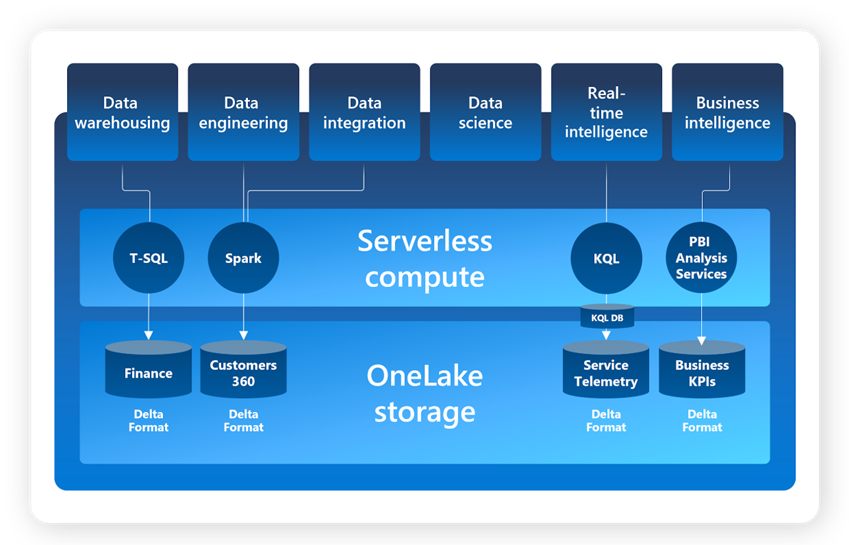
OneLake: Unified data storage system (Adapted from Microsoft)
What are the likely benefits of Fabric adoption?
A Forrester Study commissioned by Microsoft detailed the costs and benefits of moving to MS Fabric for a typical global organization that has $5 billion in annual revenue and 10,000 employees (including 40 data engineers and 400 business analysts)
Improvements envisaged for ‘technical’ users:
- Data Analysts can ‘shift left’ on the data stack and work on data preparation (including cleansing, transformation, and aggregation) without the need to switch between tools. The enhanced data governance will give them greater confidence in data quality and reliability. The AI features within Power BI will automate the detection of trends, anomalies, and key drivers
- Data Engineers benefit from a unified platform spanning ingestion (batch & real-time) to semantic data models. Purview integration provides data lineage and auditing capabilities. Developer productivity and experience are significantly improved with integration of Co-Pilot and VS Code, enabling deployment of clusters in just seconds.
The study quantifies the following improvements:
- Improved business analyst access and output by 20%.
- Increased data engineering productivity by 25%.
- Being a SaaS offering, elimination of infrastructure costs.
- Reduced data engineering time related to searching, integrating, and debugging by 90%.
Advantages for business users start with improved data access through seamless integration from Power BI, Excel, and OneLake data. Collaborative workspaces and communication tools allow work on dashboards/reports in real-time and share related insights resulting in enhanced business performance. Improved alignment between the analytics and business teams results in faster time to market.
The associated costs for Fabric adoption over a 3-year period include:
- Microsoft Fabric-related fees of $1.1 million
- Implementation costs of $1.1 million.
- Ongoing maintenance costs of $352,000
The overall NPV of benefits from adoption as per the study $9.79M representing an ROI of 379%!
A real-world perspective on MS Fabric’s potential to transform data mesh implementation
Sigmoid is involved in a multi-year data & analytics transformation that addressed some of the key issues with data architecture such as the use of legacy data tools, lack of scalability, and high costs. The evolution to Data Mesh architecture for this client was based on Data as a Product principle which helped functions such as Marketing & Sales, Supply, and Finance to convert their data (internal and external), into assets. This was underpinned by a robust architecture as illustrated below:
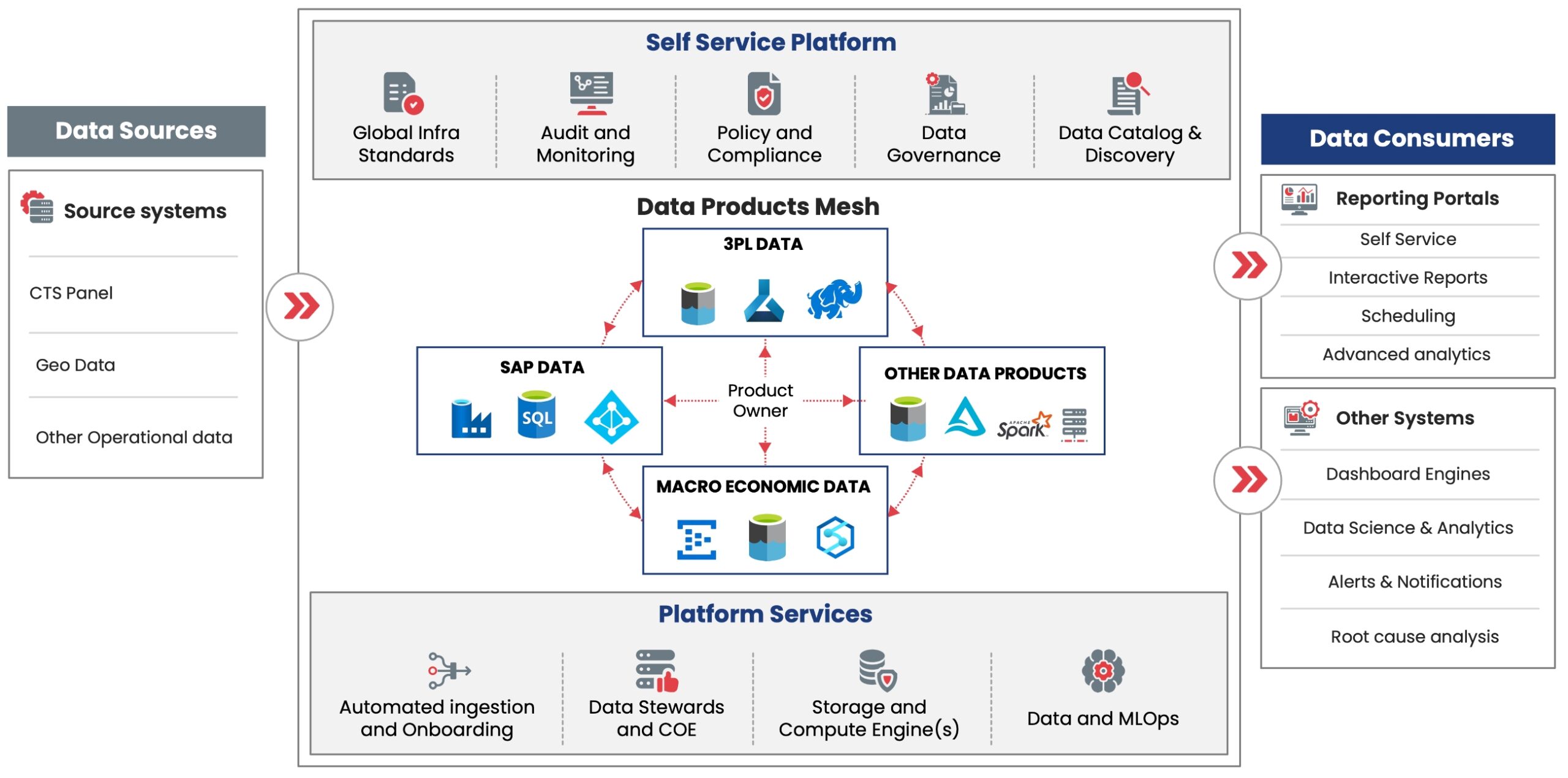
Data Mesh | Logical Architecture
An Azure-based implementation of the logical architecture had evolved into a standard platform that was centrally managed and could be leveraged by all domains.
For example, the Finance domain leveraged this platform and built data products organized into product streams and data products as follows:
- Global Financial Services > Record to Report | Procure to Pay | Order to Cash > Productivity & Operations* | Service Quality Indicators* | Benefits Tracking*
- Corporate Reporting > Management Reporting > Group Operations Leadership Reporting* | Supply Finance Reporting* | Gross Margin Analysis*
Each data product had a business case with corresponding costs & benefits being tracked. A team consisting of product managers, architects, data engineers, data visualization engineers, business analysts, and scrum masters took a product from ideation to deploy & evolve phase.
Although largely successful, the journey was not without challenges experienced on all the principles of the Data Mesh architecture. We think MS Fabric with its unified SaaS platform construct would mitigate many of the challenges experienced by the client.
The table below illustrates how MS Fabric’s capabilities align with and address the specific challenges faced during the Data Mesh journey.
| Data Mesh Architecture Principle | Azure Architecture Limitations | Supporting MS Fabric Capabilities & Features |
|---|---|---|
| Domain-oriented ownership |
|
|
| Data as a product |
|
|
| Self-serve data platform |
|
|
| Federated computational governance |
|
|
Accelerating Implementation and engineering productivity through Copilot and its integration points
Apart from enabling a de-centralized data mesh architecture an organization can also benefit from de-centralized and shorter implementation times thanks to Copilot integration with Fabric.
- Data Science and Engineering: Copilot for Data Science and Data Engineering (in preview) helps generate code in Notebooks to work with Lakehouse data, providing insights and visualizations. It supports various data sources and formats, offering answers and code snippets directly in the notebook, streamlining data analysis. You can ask questions in the chat panel, and the AI provides responses or code to copy into your notebook.
- Data Factory: Copilot offers intelligent code generation for data transformation and explanations to simplify complex tasks. It integrates with Dataflow Gen2 to generate new transformation steps, summarize queries and applied steps, and create new queries with sample data or references to existing queries.
- Data Warehouse: write and explain T-SQL queries, make intelligent suggestions, and provide fixes while coding. Key features include Natural Language to SQL, AI-powered code completion, quick actions for fixing and explaining queries, and intelligent insights based on your warehouse schema and metadata.
- Real-Time Intelligence: Co-pilot can seamlessly translate natural language queries into Kusto Query Language (KQL).
- Power BI: Quickly create report pages, natural language summaries, and generate synonyms. It assists with writing DAX queries, streamlining semantic model documentation, creating narrative visuals, and providing tailored responses to specific questions about visualized data.
In essence, Copilot can lower the technical barriers to leveraging data and analytics and in doing so enable citizen data analysts and scientists to emerge.
Conclusion
The journey to a fully mature Data Mesh architecture remains a challenge due to technical constraints and organizational obstacles. Moving from an already implemented platform and governance structure to a new one adds another layer of complexity to adoption. MS Fabric is well positioned to help organizations achieve their end state data and analytics vision. However, we think a phased approach to migration is probably best as it enables organizations to experiment, and course correct while discovering the benefits of the new SaaS paradigm of MS Fabric.
About the Authors
Gunasekaran S is the Chief of Staff, Data Engineering at Sigmoid with over 20 years of experience in consulting, system integration, and big data technologies. As an advisor to customers on data strategy, he helps in the design and implementation of modern data platforms for enterprises in the Retail, CPG, BFSI, and Travel domains to drive them toward becoming data-centric organizations.
Vinay Prabhu is the Director, Data Engineering at Sigmoid. He has over 10 years of experience across Azure, AWS data & analytics stacks. With his extensive knowledge and experience in data engineering and analytics projects, he helps enterprises in CPG, Manufacturing, and BFSI extract meaningful insights from data to drive informed decision-making.
References:
- Microsoft Fabric documentation
(https://learn.microsoft.com/en-us/fabric/) - The Total Economic Impact of Microsoft Fabric, A Forrester Total Economic Impact Study, Commissioned by Microsoft, May 2024.
(https://clouddamcdnprodep.azureedge.net/gdc/gdcbmS2K8/original) - Data Mesh Principles and Logical Architecture
(https://martinfowler.com/articles/data-mesh-principles.html)





