Containerization of PySpark using Kubernetes
Reading Time: 8 minutes

Containerization technology is widely used by data scientists and machine learning practitioners to promote the continuous deployment of models and test the models frequently while carrying out multiple iterations. In this blog, we have detailed the approach of how to use Spark on Kubernetes and also a brief comparison between various cluster managers available for Spark.
Introduction to Spark
Spark is a general-purpose distributed data processing engine designed for fast computation. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application. It supports workloads such as batch applications, iterative algorithms, interactive queries, and streaming. During execution, it creates the following components:
- Driver
- Executor
To manage these components, there is a cluster manager that takes care of resource allocation. Following are the various options available for cluster managers:
- Standalone
- Apache Mesos
- Hadoop YARN
- Kubernetes
Standalone Cluster Manager
To use Spark Standalone Cluster manager and execute code, there is no default high availability mode available, so we need additional components like Zookeeper installed and configured.
Hadoop YARN
YARN (“Yet Another Resource Negotiator”) focuses on distributing MapReduce workloads and it is majorly used for Spark workloads.
Apache Mesos
The Mesos kernel runs on every machine and provides applications with APIs for resource management, scheduling across the entire data center, and cloud environments. It provides a cluster manager which can execute the Spark code.
Kubernetes
It uses the kube-api server as a cluster manager and handles execution.
Comparison between Hadoop YARN and Kubernetes – as a cluster manager
| Features | Hadoop YARN | Kubernetes |
|---|---|---|
| Cost | For High Availability requirements that demand more than 1 nodes, minimum 3 nodes need to be running. These nodes aren’t shared for other workloads. | Here we need a running cluster which can be shared for various workloads. |
| Support | Can opt for the Cloudera (aka Hortonworks) distribution for support | Kubernetes community support. |
| Ease of setup |
There is a need to install various components on multiple nodes and these components are needed for High Availability configurations | Only Kubernetes cluster is to be up and running, code has to be part of Docker image. |
| Integrations | Relatively limited support | Supports a rich set of tools integrations. |
| Ability to isolate jobs |
To reuse the same cluster for concurrent requirements Spark apps need to compromise on isolation. | Kubernetes provides cost benefits of a shared infrastructure and full isolation. |
Brief introduction Kubernetes and its component
Kubernetes is a container orchestration engine which ensures there is always a high availability of resources. Apart from that it also has below features.
- Self-healing
- Automatic rolling updates and rollback
- Resource management
- Service Discovery
- Load Balancing
- Service Discovery
Architecture of Kubernetes
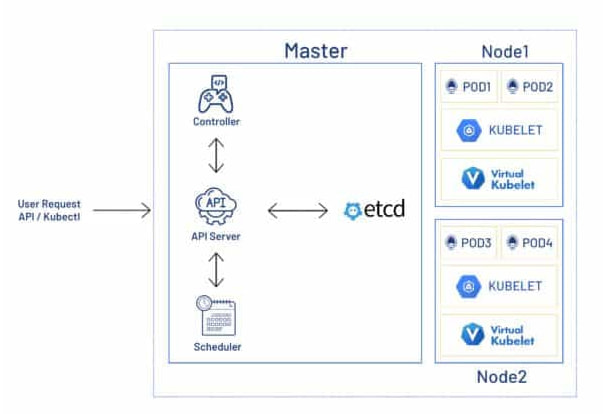
The architecture of Kubernetes has 2 major components, they are:
-
- Master Components
All the requests from the user using API, kubectl are sent to master component that is the API Server
- API Server converts json or yaml requests to http call.
- ETCD contains the details of the cluster and its components and current state.
- Controller ensures that the cluster is always in the desired state.
- Scheduler takes care of object creation based on resource availability.
- Worker Components
The following are the components that are come under the nodes:
- Kubelet is the agent which takes care of the execution of the tasks which have been assigned to it and reports back the status to the API server.
- Kube Proxy is the networking component that takes care of networking related tasks.
- Container Runtime it provides an environment on the nodes for container execution.
- Master Components
Other components –
Kubectl: is a utility used to communicate with the Kubernetes cluster.
Spark Execution on Kubernetes
Here we have explained how containerization technology with Spark is used. Below is the pictorial representation of spark-submit to API server.
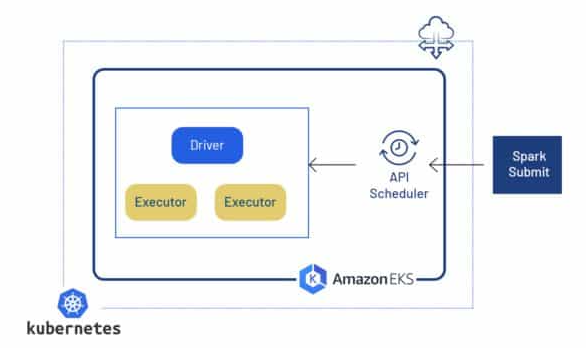
We can use spark-submit directly to submit a Spark application to a Kubernetes cluster. Once submitted, the following events occur:
- Creation of a Spark driver running as a Kubernetes pod.
- Creation of executors which are also run within Kubernetes pods connects to them and executes the application code.
- Termination and clean-up of executor pods occur when the application completes. But the driver pod persists, logs, and remains in a “completed” state in the Kubernetes API until it’s eventually garbage collected or manually cleaned up.
There are 2 options available for executing Spark on an EKS cluster
Option 1: Using Kubernetes Master as Scheduler
Option 2: Using Spark Operator
Option 1: Using Kubernetes Master as Scheduler
Below are the prerequisites for executing spark-submit using:
A. Docker image with code for execution
B. Service account with access for the creation of pods, services, secrets
C. Spark-submit binary in local machine
A. Creating Docker image for Java and Py-Spark execution
- Download Spark binary in the local machine using this link https://archive.apache.org/dist/spark/
- In this path spark/kubernetes/dockerfiles/spark there is Dockerfile which can be used to build a docker image for jar execution.
- Ensure that you are in the Spark directory as it needs jars and other binaries to be copied. So it uses all the directories as context.

Once this image is built, it can be used as a base image for the other code execution.
Docker image creation for Py Spark code execution:
In this path spark/kubernetes/dockerfiles/spark/bindings/python there is a ready Docker file which will be used for py spark execution. Ensure that you are in the Spark directory as it needs jars and other binaries to be copied so it will use all the directories as context.

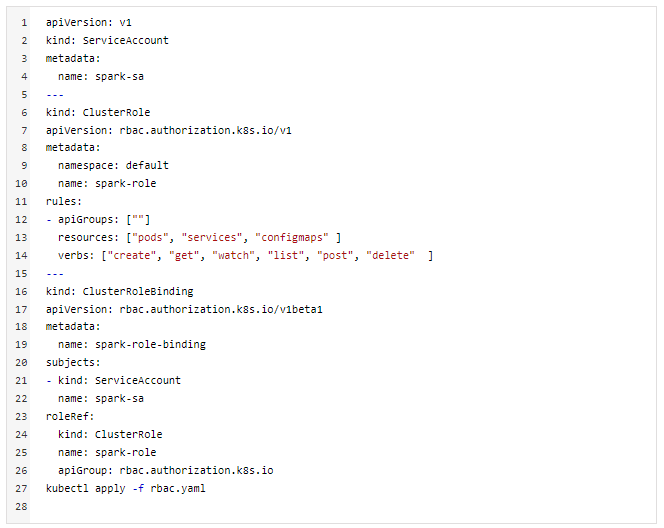
B. Creating Kubernetes service account and cluster-role binding
Components that will be used:
- Service account: an account which will be used for authentication of processes running inside the pods.
- Cluster-Role: defines the access for the service account across the cluster.
- Cluster-Role Binding: binds and creates the role with the service account.
Create a yaml file with below contents

Getting cluster information:

This command gives the master url it and it will look as shown below
Kubernetes master is running at https://ABCDZZZZZZZZZZZZZZZ.sk1.region.eks.amazonaws.com
Make a note of this URL
C. Executing Spark Submit:
Now go to the directory which has Spark binary and use the below command
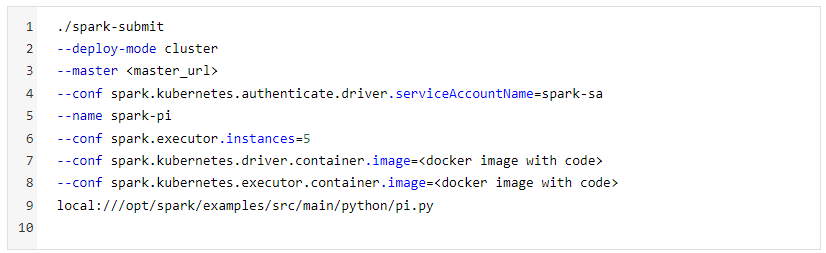

The driver and executor will be created with whatever name is specified as the app name. Using the driver pod we can view logs, access URL below commands can be used for it.
- To view logs

- To view spark ui

Additional useful options that can be used with Spark-Submit
Environment Variables:
When the script requires any environment variable that needs to be passed, it can be done using Kubernetes secret and referred to it. Details of achieving this are given below.
“spark.kubernetes.executor.secretKeyRef.DB_PASS”: “snowsec:db_pass”,
Create a secret with the name snowsec and in that db_pass is the key and which will be referred to the spark environment using DB_PASS.
Adding labels to the pod:
When we want to add additional labels to pod we can use below options
For driver pod
spark.kubernetes.driver.label.[LabelName]
For executor pod
spark.kubernetes.executor.label.[LabelName]
Using node affinity:
We can control the scheduling of pods on nodes using selector for which options are available in Spark that is
spark.kubernetes.node.selector.[labelKey]
Option 2: Using Spark Operator on Kubernetes
Operators
Operator is a method of packaging, deploying and managing a Kubernetes application. Kubernetes application is one that is both deployed on Kubernetes, managed using the Kubernetes APIs and kubectl tooling.
Using Spark Operator on Kubernetes
Official link: https://operatorhub.io/operator/spark-gcp
Installing Kubernetes Operator on EKS
Prerequisites:
- Helm needs to be installed and configured
- Verify Helm installation using below command
helm version –short
- Adding Helm repo to running EKS
- Helm repo add incubator
- Installing Helm repo on EKS :

Verify Installation:

Once applied, the below mentioned components will be created:
- Spark-operator-deployment
- Spark-serviceaccount
- Spark-rbac
- Spark-operator-serviceaccount
- Spark-operator-rbac
- Webhook-init-job
- Webhook-service
Here we need the job in yaml. Once we have yaml file, we can submit the job using the below command:

The Yaml file looks as follows:
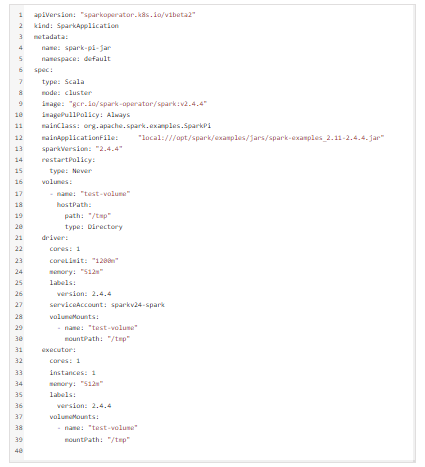
Once we submit the job, it will create 2 pods:
- Executor
- Driver
We can verify these using

We can get the logs by using below command

Details of submitted job using below command

Contains details about Web UI, service and events that occurred during creation.
Access Web UI:
To access the Web UI for a long running job can be done using port forwarding, using the below mentioned command

Conclusion
Key considerations for Production Spark code on Kubernetes
No requirement of up and running infrastructure to use Spark on EKS.
Build and Deployments
As we deploy the Docker image with the Spark submit, so when we have code changes we need to pass the docker image with Spark submit. These images can be tagged to track the changes.
Ideal Use Cases
When workload is less (e.g. 8-10 hr job executions per day) and as batch processing.
Availability/Fault Tolerance
Kubernetes has the scheduler which manages the pods created as driver and executor. This enables the usage of pods based on resource availability. Quotas for a namespace can be assigned for better resource management.
Resource Tracking
We have used node selectors in Spark submit which allows us to run specific workloads on a specific node. This in turn allows us to track the usage of resources.
Monitoring
We have integrated Spark workloads monitoring with Prometheus and Grafana, by using Kube-state-metrics and creating a dashboard. We do a Spark submit by assigning pod labels which allow us to create custom dashboards for specific labels.
Logging
We have used the ELK stack for visualizing the logs.
The approach we have detailed is suitable for pipelines which use spark as a containerized service. It also ensures optimal utilization of all the resources as there is no requirement for any component, up and running before doing Spark-submit. Additionally, Spark can utilize features like namespace, quotas along with other features of Kubernetes.
About the Author
Ajaykumar Baljoshi is a Senior Devops Engineer at Sigmoid, who currently works on Containerization, Kubernetes, DevOps and Infrastructure as Code.
Featured blogs







Featured blogs