Achieving end-to-end Database management with PERCONA XtraDB cluster
Reading Time: 4 minutes

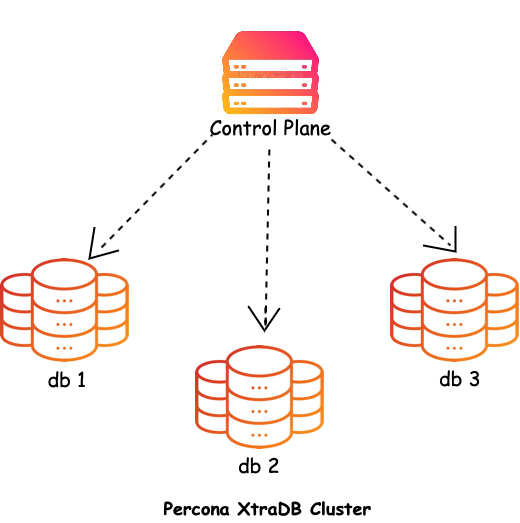
Why Percona XtraDb Cluster on Kubernetes?
Databases on kubernetes are generally associated with several complexities and DataOps engineers are always on the look out for optimal solutions. Percona offers enterprise-grade database solutions, multiple replication, migration and support with the added advantage of being an open-source technology.
We leveraged Percona in our architectural model and this not only overcomes the issue of data losses with large data transactions working on the base of Mysql cluster solutions but also provides a high availability solution.
In this blog we are going to show an easy set up process to create a clustering solution using percona with K8s, Rancher and other open source tools. Whether it is fail-safe conditions,backup-issues or monitoring dashboards this set up provides enhanced results to optimize your cloud or on-prem environment.
Pre requisites:
Kubernetes cluster set up
Helm set up
Kubectl set up
Dive Into:
-
- Run Kubectl get no (min 3 nodes cluster)
Set up Percoa-operator
We are using Percona Operator for MySQL based on Percona XtraDB Cluster
It is a Kubernetes operator to automatically manage failover scenarios.
Your app shouldn’t know anything about clustering, because it’s sorted out transparently under kubernetes-service-hostname:3306. So the app calls this address and behind it there are 3x SQLProxy/HAProxy containers (per server). Then the query is routed to one of three MySQL containers.
When the server goes down, failed SQLProxy/HAProxy and MySQL containers are removed from Kubernetes so kubernetes-service-hostname contains two instead of three members.
When the server is back online, containers are created to have a full cluster again.
There is also a Percona operator container which automatically helps to manage pods and do other actions so the cluster is fully operating.
In terms of storage, it can be just a hostPath local directory which shows a sign of simplicity from a storage perspective. You could also use PersistentVolumeClaim and any type of Storage Class behind it or external storage such as NFS.
-
-
-
-
-
-
-
- Create namespace for percona in you cluster
Kubectl create namespace percona-sql
- Create namespace for percona in you cluster
-
-
- Add Percona repository via Helm
helm repo add percona https://percona.github.io/percona- helm-charts/ helm repo update
- Add Percona repository via Helm
-
-
-
- Percona operators
helm upgrade --install pxc-operator percona/pxc-operator -- namespace percona-sql
- Percona operators
-
Set up percona-sql on rke2
-
-
-
-
-
-
-
- Create pv and storage class and pass storage class in values.yaml
Kubectl apply -f storagClass.yaml -n percona-sql kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: local-storage provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer
- Create pv and storage class and pass storage class in values.yaml
-
-
-
-
-
-
-
- Create PV,PVC as per no of pods.
Kubectl apply -f percona-pv.yaml apiVersion: v1 kind: PersistentVolume metadata: name: percona-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage-percona local: path: /mnt/percona/ nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - Node_Name
- Create PV,PVC as per no of pods.
-
-
-
-
- Install percona-sql via helm
helm upgrade --install pxc-db percona/pxc-db --set haproxy.serviceType=NodePort,haproxy.replicasServiceType=No dePort,pxc.persistence.enabled=true,pxc.persistence.storage Class=local- storage,pxc.persistence.accessMode=ReadWriteOnce,pxc.persis tence.size=10Gi -n percona-sql
- Install percona-sql via helm
-
-
-
-
-
- To access it via cli :
ROOT_PASSWORD=`kubectl -n percona-sql get secrets pxc-db -o jsonpath="{.data.root}" | base64 --decode` kubectl run -i --tty --rm percona-client --image=percona -- restart=Never \ -- mysql -h pxc-db-haproxy.percona- sql.svc.cluster.local -uroot -p"$ROOT_PASSWORD"
- To access it via cli :
-
Percona Test cases: Fail-safe conditions for data loss
1. Pods restart
Steps
-
- kubectl delete pods -n percona-sql –all
- Kubectl get po -n percona-sql
- kubectl run -i –tty –rm percona-client –
- -image=percona –restart=Never — mysql -h pxc-db-haproxy.percona-
sql.svc.cluster.local -uroot -p”insecure-root-password” - validate your data
Results(Impact:Data Loss/No Data Loss)
Impact: data Loss
(No pv attached to pvc)
2. pv/pvc attach detach
Steps
- Attach additional pv&pvc to the pxcdb and ha-proxy
- vi percona-pv.yaml
apiVersion: v1 kind: PersistentVolume metadata: name: percona-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage-percona local: path: /mnt/percona/ nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values:Node_Name -- vi percona-pvc.yaml
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: percona-pvc namespace: percona-sql spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: local-storage-percona- Kubectl apply -f percona-pv.yaml -n percona-sql
- Kubectl apply -f percona-pvc.yaml
-n percona-sql - Change values.yaml and then redeploy it.
-
Results(Impact:Data Loss/No Data Loss)
Impact:No data Loss
Description: Pvc/pv retains data
3. Node crash/Node detach
-
- Each pv is attached to each node
- If one node crash due to failure other pv’s can retain data.
-
-
Impact:No data Loss if pvc is attached
4. Pxc cluster delete/crash
Kubectl get pxc -n percona-sql
Impact: No data Loss if external pv (disk/local storage ) is attached even after pxc operator cluster deletion if remain (claim policy should be set to retain)
Conclusion:
We set up percona XtraDB on rke2 and tested it’s fail safe conditions that generally cause the problem of data loss. Preventing initial data loss rather than having a backup and restoring it was also one of the main highlights of this approach. Feel free to reach out to us at www.sigmoid.com/contact-us/ if you have any queries.
About the author
Akansha Immanuel is a DevOps Engineer at Sigmoid. She is a tech enthusiast and a voracious reader. She believes in dynamic progression in DevOps, and has also worked on several DataOps projects for large data producers and currently exploring FinOps.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-




